私はこれまで数多くのAIツールや検索エンジンを試してきましたが、Brave SearchとModel Context Protocol(MCP)の組み合わせは別格です。
プライバシーを保護しつつ、AIにリアルタイムなウェブ情報を与えるための最適解と言い切れます。
Brave SearchとMCPが選ばれる理由
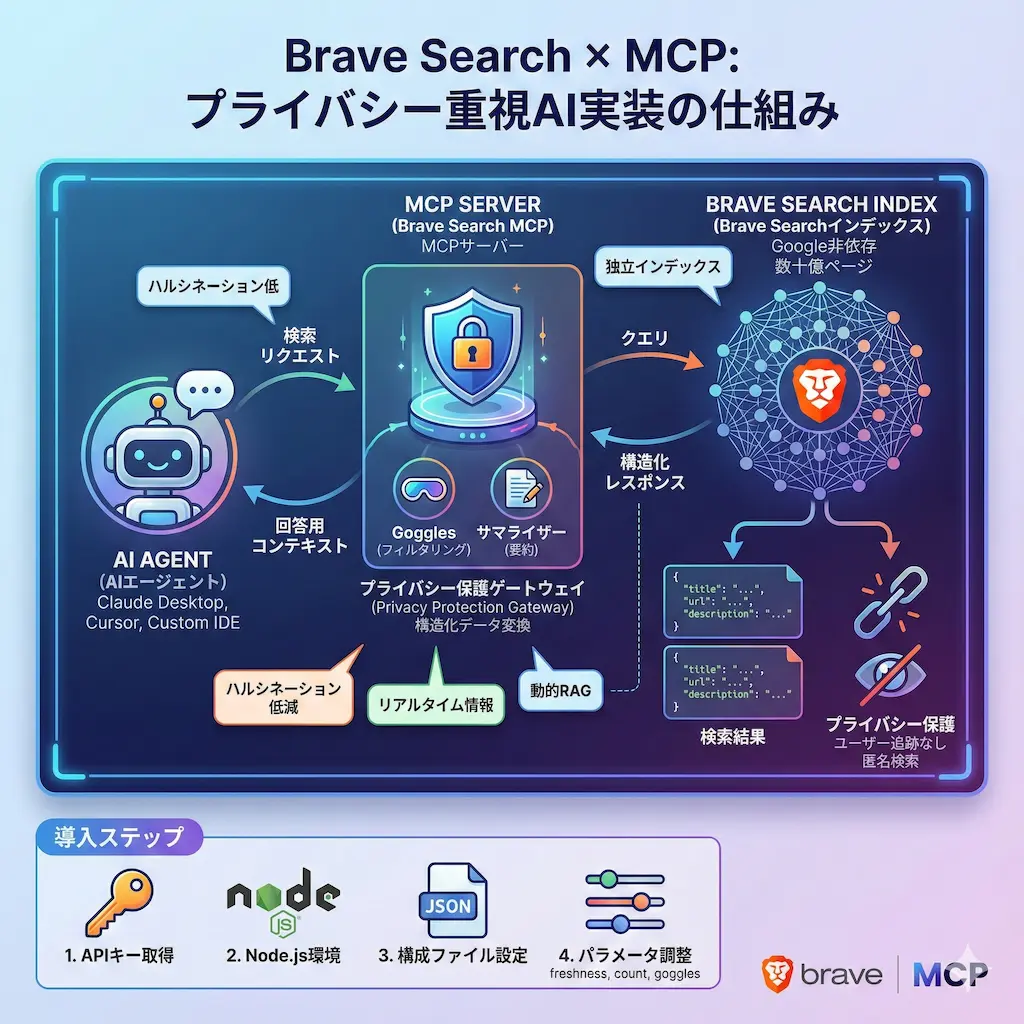
現代のAI開発において、大規模言語モデル(LLM)と外部データの接続は最重要課題です。Brave Search MCPサーバーは、単なる検索APIのラッパーではなく、AIエージェントの自律性と信頼性を根本から変えるインフラストラクチャとして機能します。
独立したインデックスによるプライバシー保護
Brave Searchの最大の特徴は、GoogleやBingに依存しない独自のインデックスを持っている点です。多くのAIモデルがGoogleの検索結果に依存している現状では、特定のアルゴリズムバイアスや商業的なフィルタリングがAIの回答に影響を与えてしまいます。Braveは独自のウェブクローラー「Bravebot」を運用しており、数十億ページ規模のインデックスを構築しています。
企業ユースにおいて、検索履歴の追跡はセキュリティ上の懸念事項です。Brave Search MCPを使用することで、ユーザーのプロファイル構築や追跡を行わない検索環境を手に入れられます。競合調査や内部技術に関連する検索を行う際、外部に情報が漏れるリスクを遮断できる点は大きな強みです。
AIのために設計されたデータ構造
Braveは「Data for AI」というコンセプトを掲げ、人間用ではなくAI用のデータ提供に特化しています。従来の検索APIは青いリンクのリストを返すだけでしたが、Brave Search MCPはLLMが解釈しやすい構造化メタデータを提供します。
エンティティや場所、製品情報などのデータポイントがあらかじめ整理されたJSON形式で返ってきます。これにより、LLMは重いHTML解析処理をする必要がなく、直接的な知識としてデータを取り込めます。開発者はトークン消費を抑えつつ、密度の高い情報をエージェントに与えることができます。
構造化データの活用例
例えば、レストラン検索を行う場合を考えてみましょう。通常の検索ではWebサイトを開いて情報を探す必要がありますが、Brave Search MCPは最初から「住所|評価|営業時間」といった重要情報を構造化して返します。この仕組みにより、エージェントは即座に比較検討や予約提案へ移行できます。
サマライザー機能の統合
Braveには検索結果全体を要約する「Summarizer」機能があります。これをMCP経由で利用することで、複雑なトピックに対する即時の回答生成が実現します。複数のソースを確認する手間を省き、核心的な情報だけを抽出するプロセスはAIの応答速度を劇的に向上させます。
実践的な導入手順と設定方法
ここからは、実際にBrave Search MCPサーバーを導入するための具体的な手順を解説します。今回は現在最もポピュラーなクライアントであるClaude Desktopでの設定を例に進めます。
必要な環境と初期設定
導入にはAPIキーの取得とNode.js環境の準備が必要です。これらは一度設定すれば、永続的に利用できます。
APIキーの取得とNode.js
Brave APIダッシュボードからAPIキーを取得します。クレジットカード登録が必要ですが、フリーティアで月間2,000クエリまで利用できるため、個人の開発やテストには十分な量です。
次にNode.jsの実行環境を確認します。システムレベルでのトラブルを避けるため、nvm(Node Version Manager)を使用した環境構築を強く推奨します。Windowsユーザーの方はパス設定でつまずくことが多いため、環境変数にnpmが含まれているか確認してください。
Claude Desktopでの構成ファイル記述
Claude Desktopの設定ファイルclaude_desktop_config.jsonに以下の設定を記述します。これにより、ClaudeがローカルでBrave Searchサーバーをサブプロセスとして起動できるようになります。
{
"mcpServers": {
"brave-search": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-brave-search"
],
"env": {
"BRAVE_API_KEY": "YOUR_API_KEY_HERE"
}
}
}
}commandにnpxを指定することで、パッケージをインストールせずに実行時に取得して起動します。-yフラグは確認プロンプトをスキップするために必須です。環境変数BRAVE_API_KEYはこのプロセス内だけで有効になるため、安全性が保たれます。
検索精度を高めるパラメータ調整
Brave Search MCPの真価は、デフォルト設定から一歩踏み込んだパラメータ調整にあります。目的に応じて設定を変えることで、汎用的な検索から特化型のエージェントへと進化します。
検索クエリと鮮度のコントロール
ニュースや最新技術を扱うエージェントの場合、情報の鮮度が命です。freshnessパラメータを適切に設定することで、古い情報を排除しハルシネーションを防ぐことができます。
| パラメータ | 設定値 | 効果 |
|---|---|---|
| pd | 過去24時間 | 速報ニュースや株価情報の取得に最適 |
| pw | 過去1週間 | 最近のトレンドやイベント情報の収集向け |
| pm | 過去1ヶ月 | 月次の動向調査やまとまった情報の取得 |
| py | 過去1年 | 年間の技術変遷や長期的なレビュー確認 |
countパラメータはデフォルトで10ですが、最大20まで増やせます。コンテキストウィンドウの消費量と相談しながら、情報の網羅性を調整してください。
Gogglesによる情報ソースの最適化
Brave独自の機能「Goggles」を使うと、検索ランキングのアルゴリズムを自分好みに書き換えられます。特定のドメインを上位表示したり、逆にSEOスパムサイトを除外したりできます。
例えば、プログラミングの質問に対しては技術ドキュメントやGitHubのみを検索対象にするGoggleを設定します。エージェントのシステムプロンプトにGoggleのURLを渡すことで、ノイズのない高品質な回答生成が実現します。これは他の検索エンジンAPIにはない強力な差別化要素です。
導入前に知っておくべきメリットとデメリット
Brave Search MCPは非常に強力ですが、万能ではありません。導入を検討する際は、以下のメリットとデメリットを比較検討してください。
Brave Search MCPのメリット
最大のメリットは、プライバシーと情報の質のバランスが取れている点です。ユーザーの行動を追跡せず、かつGoogleに依存しない独立した情報源を持つことで、AIエージェントに「セカンドオピニオン」を提供できます。
また、構造化データの提供により、RAG(検索拡張生成)の効率が飛躍的に向上します。不要なHTMLタグを排除したクリーンなJSONデータは、LLMのコンテキストウィンドウを節約し、より多くの情報を処理させる余地を生み出します。さらに、Gogglesによる検索結果のキュレーション機能は、特定のドメインに特化した専門エージェントを作る際に必須の機能です。
Brave Search MCPのデメリット
一方で、導入には技術的なハードルがあります。APIキーの管理やJSONファイルの編集が必要なため、非エンジニアにとっては設定が少し複雑に感じる場面があります。
フリーティアの制限にも注意が必要です。1秒あたり1リクエストというレート制限があるため、頻繁な検索を行う本番環境のアプリケーションでは有料プランへのアップグレードが必須になります。Python環境での利用を考えている場合、公式サーバーがTypeScript製であるため、Node.jsのランタイムが必要になる点も環境によっては手間になります。
次世代のAI検索体験へ
Brave Search MCPサーバーは、プライバシーを重視する現代のAI開発において、なくてはならない基盤技術です。独立したインデックスと構造化データ、そしてMCPという標準規格の組み合わせは、これまでの「検索して終わり」という体験を過去のものにします。
AIエージェントが自律的に最新情報を取得し、検証し、ユーザーに最適な回答を生成する。この一連の流れをセキュアに構築できる点が、私がこのツールを強く推奨する理由です。あなたのAIプロジェクトに今すぐBrave Searchを組み込み、その違いを体感してください。