データ分析や機械学習を学び始めると、必ず直面する壁があります。それが「線形回帰とロジスティック回帰、どっちを使えばいいの?」という疑問です。
私はこれまで多くのデータ分析案件に関わってきましたが、この二つのモデルの選択を間違えると、分析結果が全く役に立たないものになってしまいます。どちらも「回帰」という名前がついていますが、その役割と得意分野は明確に異なります。
この記事では、数式に苦手意識がある方でも直感的に理解できるように、二つの違いと使い分けのポイントを徹底解説します。
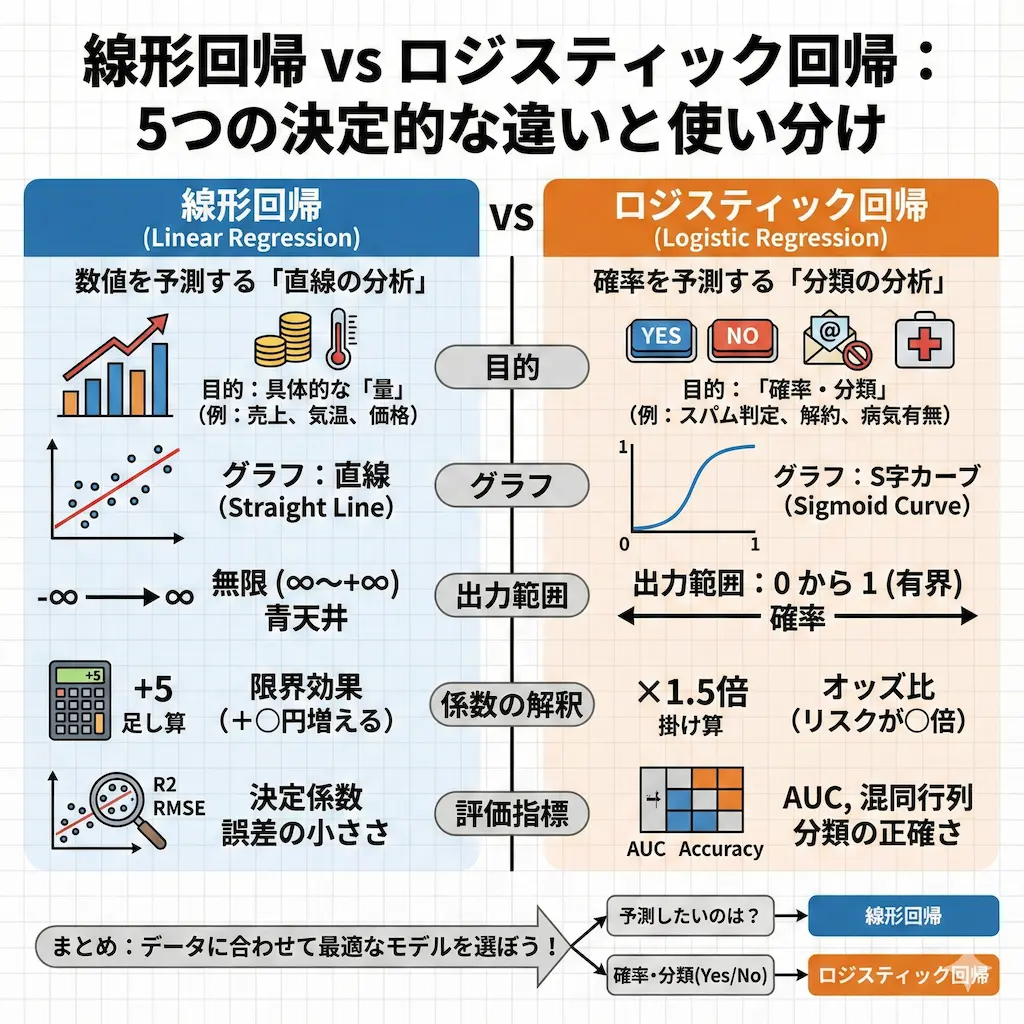
基礎知識|線形回帰とロジスティック回帰とは何か
データサイエンスの世界には様々な分析手法が存在しますが、線形回帰とロジスティック回帰はその中でも最も基本的かつ強力なツールです。
私が初心者に教えるときは、シンプルに「何を予測したいか」で区別するように伝えています。結論から言えば、数値を予測したいなら線形回帰、確率や分類を予測したいならロジスティック回帰を選びます。
線形回帰|数値を予測する「直線の分析」
線形回帰(Linear Regression)は、連続的な数値を予測するための手法です。
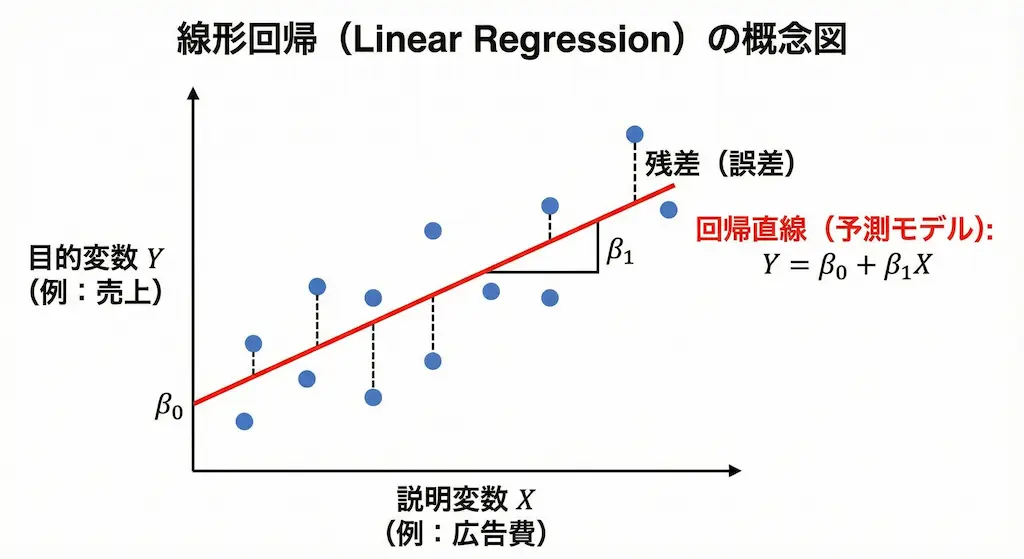
私がデータ分析を始めた頃、最初に取り組んだのがこの線形回帰でした。入力したデータと出力したい結果の間にある「直線的な関係」を見つけ出し、数式化します。
具体的な活用シーン|売上や気温の予測
ビジネスの現場では、線形回帰は非常に多くの場面で活躍します。たとえば、広告費をいくら使えば売上がどれくらい伸びるかといった予測です。
「広告費を10万円増やせば、売上は平均50万円増える」といった具体的な数値を算出できます。他にも、明日の気温予測や不動産価格の推定など、具体的な「量」を知りたい場面で私は必ずこの手法を検討します。
予測値の範囲に制限がない
線形回帰の特徴は、予測される値に上限や下限がないことです。計算結果はマイナス無限大からプラス無限大まで、どのような値も取り得ます。
これが売上金額のような青天井のデータには適していますが、0から100%の間に収まるべき確率の予測には向いていません。私が過去に失敗した経験ですが、線形回帰で確率を計算しようとして「降水確率120%」というあり得ない数字を出してしまったことがあります。
ロジスティック回帰|確率を予測する「分類の分析」
ロジスティック回帰(Logistic Regression)は、その名前に「回帰」と付いていますが、実際には「分類」を行うための手法です。
ある事象が起こるか起こらないか、つまり「YesかNoか」を予測する場面で威力を発揮します。出力されるのは0から1の間の数値であり、これを確率として解釈します。
具体的な活用シーン|病気の有無やスパム判定
私がよく例に出すのは、メールのスパム判定機能です。
届いたメールが「スパムである(Yes)」か「スパムでない(No)」かを判定する際に、ロジスティック回帰は使われています。医療現場における生存確率の予測や、Webマーケティングでの購入確率の予測など、白黒はっきりさせたい問題に対して私はこのモデルを採用します。
なぜ「回帰」という名前なのか
分類を行う手法なのに、なぜ「回帰」という名前がついているのか不思議に思うかもしれません。
実は、線形回帰とロジスティック回帰は「一般化線形モデル(GLM)」という同じ数理的な祖先を持っています。私が専門的な本を読み解いた際、ロジスティック回帰は「確率の対数オッズ」という数値を回帰分析していることを知りました。根っこの部分では兄弟のような関係にあるため、名前が似ているのです。
線形回帰とロジスティック回帰の比較表
私が実務で確認用に作成している簡易比較表を掲載します。
| 項目 | 線形回帰 | ロジスティック回帰 |
|---|---|---|
| 目的変数 | 連続値(金額、温度など) | カテゴリカル変数(Yes/No) |
| 予測の目的 | 量の予測 | 確率・分類の予測 |
| 出力範囲 | 無限(制限なし) | 0 から 1 の間 |
| グラフの形 | 直線 | S字カーブ(シグモイド曲線) |
| 主な用途 | 売上予測、需要予測 | 解約予測、不正検知 |
仕組みの違い|数学的な背景とグラフの形状
二つのモデルは計算のアプローチや前提条件が大きく異なります。
私が分析結果を報告する際、この仕組みの違いを理解していないと、クライアントに誤った説明をしてしまうリスクがあります。ここでは数式を極力使わずに、その本質的な違いを掘り下げます。
グラフの形|直線とS字カーブの違い
視覚的に最もわかりやすい違いは、データをグラフにしたときの形状です。
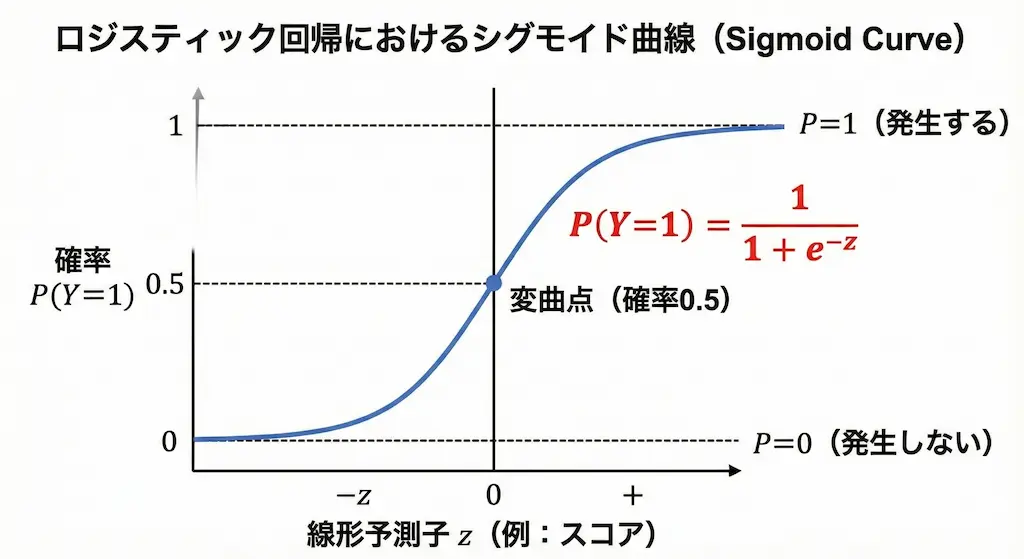
線形回帰はデータを真っ直ぐな「直線」で近似しようとします。これに対し、ロジスティック回帰は「S字カーブ(シグモイド曲線)」を描きます。
確率を表現するためのシグモイド関数
確率の世界では、値は必ず0と1の間に収まらなければなりません。
ロジスティック回帰で使われるシグモイド関数は、どんなに大きな入力値があっても1に近づくだけで1を超えず、どんなに小さな値でも0を下回りません。私がこのカーブを初めて見たとき、現実世界の「ある程度勉強すると急に点数が伸び、やがて頭打ちになる」という現象をうまく表していると感じました。
最小二乗法と最尤推定法
計算手法にも大きな違いがあります。線形回帰では、実際のデータと直線のズレ(誤差)を最小にする「最小二乗法(OLS)」を使います。
一方でロジスティック回帰では、観測されたデータが発生する確率が最大になるようなパラメータを探す「最尤推定法(MLE)」を用います。私がモデルを構築する際、線形回帰は一発で計算が終わりますが、ロジスティック回帰はコンピュータが試行錯誤を繰り返して答えを見つけるため、データ量が多いと計算時間がかかることがあります。
係数の解釈|足し算と掛け算
ビジネスで分析結果を活用するには、算出された係数(パラメータ)の意味を理解することが不可欠です。
私が経営陣に説明する際、この解釈の違いが最も重要なポイントになります。線形回帰は直感的ですが、ロジスティック回帰は少し慣れが必要です。
線形回帰は「限界効果」
線形回帰の係数は「足し算」の世界です。
たとえば「年齢」の係数が「+5」であれば、「年齢が1歳上がると、予測値は常に5増える」と解釈できます。私が予算策定のシミュレーションを行うときは、この単純明快さが非常に役立ちます。「広告費を増やせば、そのまま比例して売上が伸びる」という説明ができるからです。
ロジスティック回帰は「オッズ比」
ロジスティック回帰の係数は「掛け算」あるいは「倍率」の世界に近いものです。
ここでは「オッズ比」という指標を使います。係数が正の場合、「その変数が1増えると、事象が起こるオッズ(見込み)が〇倍になる」と解釈します。私がマーケティング担当者に説明するときは、「確率が何倍になる」とは言わず、「リスクが何倍高まる」といった表現を使って誤解を防ぐよう心がけています。
モデルの評価指標|R2と精度の違い
作ったモデルが良いのか悪いのかを判断する基準も異なります。
私が初心者の頃、線形回帰の指標をそのまま分類問題に当てはめようとして混乱したことがありました。それぞれのモデルには、適切な「通知表」が存在します。
決定係数とRMSE
線形回帰の性能は、主に「決定係数(R2)」や「RMSE(二乗平均平方根誤差)」で評価します。
決定係数は「データのばらつきをどれだけ説明できているか」を0から1で表します。私が実務で目安にするのは、R2が0.7以上あればかなり当てはまりが良いという感覚です。RMSEは実際の誤差の大きさを表すので、「予測は平均して〇〇円ずれる」といった具体的な評価ができます。
混同行列とAUC
ロジスティック回帰のような分類問題では、「混同行列(Confusion Matrix)」を使います。
これは「正解を正解と当てられた数」や「間違いを見逃した数」を表にしたものです。ここから正解率(Accuracy)や適合率(Precision)などを算出します。さらに、私がモデルの優劣を競う際は、閾値に依存しない評価指標である「AUC(Area Under the Curve)」を最重要視します。
実践的な使い分け|ビジネス現場での判断基準
理論がわかったところで、実際のビジネス課題に対してどう使い分けるべきかを見ていきましょう。
私がプロジェクトに参加する際は、まず「最終的なアウトプットがどうあるべきか」から逆算してモデルを選定します。
目的変数のタイプで見極める
最も確実な判断基準は、予測したい対象(目的変数)のデータ型を確認することです。
もしデータが「販売個数」や「来店者数」のようなカウントデータ、あるいは「金額」であれば、迷わず線形回帰(またはその応用)を選びます。逆に「会員登録したか」「クリックしたか」というフラグであれば、ロジスティック回帰一択です。
小売業のケーススタディ|在庫管理
私が小売チェーンのデータ分析を担当した際、翌月の「商品販売数」を予測する必要がありました。
この場合、知りたいのは「売れる確率」ではなく「何個在庫を確保すべきか」という具体的な数量です。そのため、過去の販売実績や経済指標を説明変数として、線形回帰モデルを構築しました。これにより、「気温が1度上がるとビールが平均30本多く売れる」といった知見が得られ、発注精度の向上に貢献できました。
金融業のケーススタディ|解約予測
クレジットカード会社でのプロジェクトでは、「解約しそうな顧客」を見つけることがミッションでした。
ここでは「解約するかしないか」の二値分類が必要になります。私が採用したのはロジスティック回帰です。単に解約者を当てるだけでなく、「この顧客の解約確率は80%」というスコアが出せるため、確率が高い順にキャンペーンメールを送るといった優先順位付けが容易に行えました。
説明責任と解釈のしやすさ
モデルの精度だけでなく、「なぜその予測になったか」を説明できるかどうかも選定のポイントです。
最近はAIによるブラックボックス化が懸念されていますが、線形回帰やロジスティック回帰は「どの要因がどれくらい効いているか」が明確に見えます。
線形回帰は直感的な理解が容易
線形回帰の結果は、専門知識がない人にも非常に伝えやすいです。
「AをすればBになる」という関係が直線的であるため、施策のインパクトが見積もりやすいのです。私が経営会議でプレゼンをする際、複雑な数式よりも「この施策で売上が平均〇〇円上がります」と言い切れる線形モデルの結果は、意思決定をスムーズにします。
ロジスティック回帰は要因分析に強い
ロジスティック回帰も、オッズ比を使うことで要因の影響度を説明できます。
「コールセンターへの問い合わせ回数が多いほど、解約リスクが1.5倍になる」といった具体的なインサイトが得られます。私が顧客分析を行う際は、予測精度を追求するランダムフォレストなどの手法と並行して、あえてロジスティック回帰を実行し、現状の要因分析(何が効いているか)を把握するために使うことがよくあります。
まとめ|データに合わせて最適なモデルを選ぼう
線形回帰とロジスティック回帰は、データ分析の基本にして奥義とも言える手法です。
私がこの記事で伝えたかったことは、両者の違いは単なる計算式の違いではなく、「世界をどう捉えるか」というアプローチの違いだということです。数値を直線で捉えるか、確率をS字カーブで捉えるか。この視点を持つだけで、分析の質は格段に上がります。
最後に、今回のポイントを振り返ります。
- 数値を予測したいなら線形回帰、確率や分類ならロジスティック回帰
- 線形回帰は「足し算」で直感的、ロジスティック回帰は「オッズ比」で確率的
- モデルの評価には、それぞれに適した指標(R2やAUC)を使う
どちらのモデルも、現代のビジネスにおいて強力な武器になります。ぜひ、目の前のデータが何を語りたがっているのかを見極め、適切なモデルを選んでみてください。