私たちが普段何気なく使っている言葉には、辞書的な意味だけでなく文脈や連想といった複雑な背景があります。最近のAIが人間のように自然な会話を繰り広げられるのは、この「意味」を計算可能なデータとして扱えるようになったからです。
私がAIの学習メカニズムに触れた際、最も興味深いと感じたのが、知識を網の目のようにつなげて考える「意味ネットワーク」という概念でした。この記事では、AIがどのようにして言葉の意味を理解し、知識を蓄積しているのか、その基礎となる技術と歴史的な進化について分かりやすく解説します。
意味ネットワークとは|言葉のつながりを可視化する技術
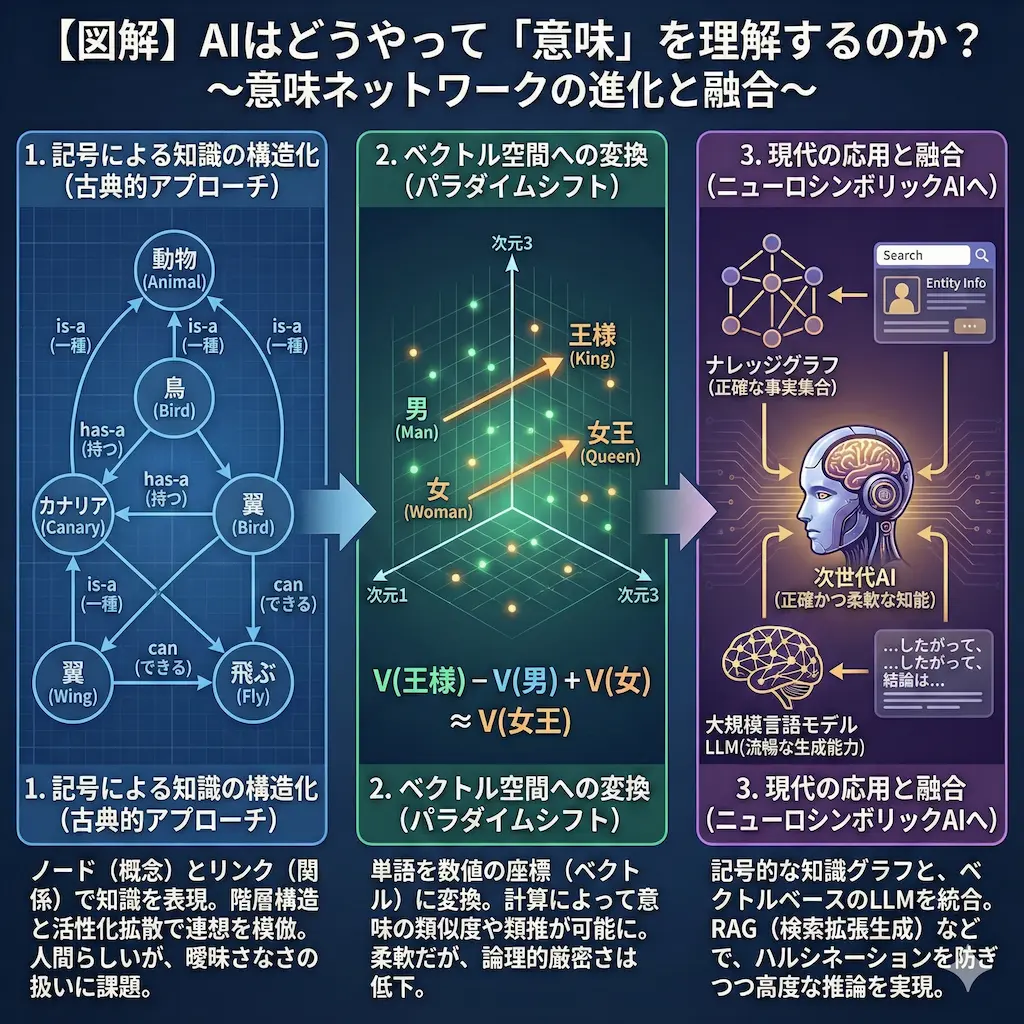
意味ネットワークは、人間の脳内にある知識の構造をモデル化したものです。言葉や概念を点(ノード)で表し、それらの関係を線(リンク)で結ぶことで、意味を定義します。
この仕組みを理解すると、AIがどのように「思考」しているかのイメージが掴みやすくなります。まずは基本的な構造とメカニズムを見ていきましょう。
人間の記憶をモデル化した知識表現
人間は単語を単体で記憶しているわけではありません。「リンゴ」と聞けば「赤い」「果物」「甘い」といった関連情報を瞬時に思い浮かべます。
意味ネットワークは、この連想ゲームのような脳の働きをコンピュータ上で再現するためのアプローチです。知識をバラバラのデータではなく、つながり合った構造として扱います。
ノードとリンクで描く概念地図
意味ネットワークの基本要素は非常にシンプルです。概念を表す「ノード」と、関係を表す「リンク」の2つだけで構成されます。
- ノード(Node)|「鳥」「翼」「飛ぶ」といった具体的な概念や単語
- リンク(Link)|「~である(is-a)」「~を持つ(has-a)」といった関係性
例えば「カナリア」というノードは、「鳥」というノードと「is-a(一種である)」というリンクで結ばれます。さらに「鳥」ノードは「翼」ノードと「has-a(持つ)」で結ばれるのです。
このように情報をネットワーク状につなげることで、コンピュータは「カナリアは翼を持っている」という事実を推論できます。人間にとっては当たり前のことでも、機械にとっては画期的な進歩でした。
キリアンが提唱した初期モデル
この概念を最初に体系化したのは、M.ロス・キリアンという研究者です。彼は1960年代に、人間の意味記憶をシミュレートする「Teachable Language Comprehender(TLC)」というモデルを発表しました。
私がこのモデルを知って驚いたのは、その着眼点の鋭さです。キリアンは、辞書のように定義を並べるのではなく、言葉同士の関係性そのものが「意味」であると考えました。
- 概念は孤立して存在しない
- 意味は他の概念との関係性によって定義される
- 知識は階層構造を持つ
この構造主義的なアプローチは、その後のAI研究における知識表現のスタンダードとなりました。現代のWeb検索やデータベースの基礎も、この考え方にルーツを持っています。
コンピュータが「連想」する仕組み
意味ネットワークの真価は、静的な図を描くことではなく、そこから情報を検索・推論するプロセスにあります。人間が「あ、そういえば」と思い出す過程を、アルゴリズムとして実装しているのです。
コンピュータはこのネットワークを辿ることで、直接教えられていない関係性を見つけ出します。
活性化拡散モデルの基本原理
特定の単語を聞いたとき、関連するイメージが次々と浮かんでくる現象を「活性化拡散」と呼びます。「消防車」と聞けば「赤」が思い浮かび、そこから「リンゴ」「ポスト」へと連想が広がるような動きです。
コンピュータ上のモデルでは、あるノードが刺激を受けると、そのエネルギーがリンクを通じて隣接するノードへ波紋のように広がっていきます。
- 探索の起点を決める(例|「病院」と「医者」)
- リンクを辿って探索範囲を広げる
- 探索の波が交差する地点を見つける(例|「治療」)
このプロセスにより、AIは文脈に関連性の高い単語を選び出せるようになります。検索エンジンが、キーワードに関連する別の言葉をサジェストできるのもこの理屈です。
芋づる式に情報を引き出す検索手法
キリアンのモデルでは「交差探索」という手法が用いられました。2つの概念の共通点や関係性を探るために、それぞれのノードから探索を開始し、ぶつかった場所を答えとする方法です。
例えば「植物」と「生きる」の関係を知りたい場合、双方からネットワークを辿っていくと「成長する」というノードで出会うかもしれません。これにより「植物は生きているから成長する」という文脈が形成されます。
私がAIの挙動を観察していて面白いと感じるのは、この探索プロセスが人間の「ひらめき」に似ている点です。遠く離れた概念同士がつながった瞬間、新しい意味が生まれるのです。
意味ネットワークの歴史と進化|記号からベクトルへ
初期のモデルは画期的でしたが、人間の複雑な認識をすべて表現するには限界がありました。AI研究の歴史は、このモデルをいかに人間に近づけるかという試行錯誤の連続です。
記号を使った論理的なアプローチから、数値を駆使した統計的なアプローチへの変遷を解説します。
心理学的な実験と理論の修正
意味ネットワークが単なるプログラム上のデータ構造ではなく、心理学的にも妥当性があるかを検証する実験が行われました。その結果、人間の脳はもっと柔軟で、いい加減な処理をしていることが判明したのです。
カナリアは鳥か?反応時間の実験
コリンズとキリアンは、被験者に文章の真偽を判断させ、その反応時間を測定する実験を行いました。「カナリアはカナリアだ」「カナリアは鳥だ」「カナリアは動物だ」という順に、カテゴリーの階層が上がるほど判断に時間がかかると予測したのです。
実験結果は彼らの仮説を概ね支持しました。脳内で概念の階層を辿る「移動時間」が存在することが示唆されたわけです。
- レベル0|カナリアはカナリア(即答)
- レベル1|カナリアは鳥(少し時間がかかる)
- レベル2|カナリアは動物(さらに時間がかかる)
この結果は、知識が階層的に整理されて保存されている証拠とされました。効率的に情報を引き出すための「認知的経済性」が働いているのです。
典型性効果によるモデルの限界
きれいな階層モデルには説明できない例外も見つかりました。人間は「ロビン(コマツグミ)は鳥だ」と判断するより、「ニワトリは鳥だ」と判断するほうが遅かったのです。
論理的な階層構造では、ロビンもニワトリも同じ「鳥」の下にあるはずです。しかし人間は「典型的な例」ほど早く反応し、例外的でおなじみが薄いものほど遅くなる傾向があります。
- 典型的な鳥(スズメ、カラス)|反応が速い
- 非典型的な鳥(ペンギン、ダチョウ)|反応が遅い
この「典型性効果」により、厳密なロジックだけでなく、頻度や類似度といった「あいまいな要素」を取り入れる必要が出てきました。
論理的な厳密さを求めた改良
1970年代に入ると、意味ネットワークの「リンク」の定義が曖昧すぎると批判を受けるようになります。なんとなく線を引くだけでは、複雑な論理を表現できないことが露呈しました。
「リンク」の定義に対するウッズの批判
ウィリアム・ウッズは、リンクが「定義(クラス関係)」を表しているのか、「事実(属性値)」を表しているのかが混同されていると指摘しました。
例えば「ジョンは背が高い」という属性と、「ジョンはボールを打った」という出来事は、グラフ上では似たような線に見えます。しかし論理的な意味合いは全く異なります。
- 構造的リンク|言葉の定義や普遍的な真理
- 主張的リンク|一時的な事実や出来事
この区別をつけないと、AIは誤った推論をしてしまいます。「すべての少年は犬が好き」という文も、「特定の犬」なのか「それぞれの犬」なのか区別がつきません。より厳密なルール作りが求められました。
フレーム理論との融合と発展
この問題を解決する一つの手段として、マービン・ミンスキーの「フレーム理論」が影響を与えました。概念を単なる点ではなく、枠組み(フレーム)を持った構造体として扱います。
「部屋」というフレームには、あらかじめ「床」「壁」「天井」といったスロット(空欄)が用意されています。これにより、情報を整理しやすくなり、欠けている情報を推測することも容易になります。
現在のプログラミングにおける「オブジェクト指向」の考え方は、この流れを汲んでいます。クラス(設計図)とインスタンス(実体)を分けることで、知識を効率的に管理できるようになったのです。
ベクトル空間モデルへのパラダイムシフト
21世紀に入り、ディープラーニングの登場によって知識表現の方法は劇的に変化しました。「言葉を記号として扱う」ことから「言葉を数値の集まりとして扱う」ことへの転換です。
Word2Vecがもたらした革命
2013年、Googleの研究者たちが「Word2Vec」を発表しました。これは単語を数百次元のベクトル(数値の列)に変換する技術です。
これまでの意味ネットワークは人間が手作業で線を引いていましたが、Word2Vecは大量のテキストデータを読み込ませることで、単語同士の関係性を自動的に学習します。
- 意味が近い単語は、ベクトル空間で近くに配置される
- 単語の意味を足し算や引き算で計算できる
「王様 - 男 + 女 = 女王」という計算が成り立つことが示されたとき、世界中の研究者が衝撃を受けました。意味を数学的な空間上の「位置」として捉えられるようになったのです。
数値計算で「意味」を捉える方法
ベクトル空間モデルでは、明示的なリンク線は存在しません。代わりに、ベクトル同士の「距離」と「方向」がリンクの役割を果たします。
私がこの技術に感動するのは、人間が定義しきれない微妙なニュアンスまで捉えられる点です。「楽しい」と「面白い」の微妙な違いや、文脈による意味の変化も、数値の近さとして表現できます。
- 従来のモデル|0か1かのデジタルな関係
- ベクトルモデル|連続的でアナログな関係(類似度90%など)
これにより、AIは曖昧な表現や類推を扱えるようになり、翻訳精度や文章生成の能力が飛躍的に向上しました。
現代AIにおける応用と未来|LLMとナレッジグラフ
現在、私たちが利用している最新のAIサービスは、これまでの意味ネットワークの概念を高度に応用したものです。具体的にどのような形で技術が使われているのか見てみましょう。
セマンティックウェブとGoogleの検索技術
Webの世界でも、情報の意味をコンピュータに理解させようとする動きが進んでいます。「セマンティックウェブ」という構想です。
巨大な知識の網「ナレッジグラフ」
Googleで有名人を検索すると、右側にプロフィールや関連人物がまとまったボックスが表示されることがあります。これは「ナレッジグラフ」と呼ばれる巨大な意味ネットワークから情報を引き出しています。
ナレッジグラフは、世界中のあらゆる事物(エンティティ)をノードとし、それらの事実関係をリンクで結んだデータベースです。
- 誰が誰の親か
- どの作品を誰が作ったか
- どの場所がどこにあるか
これらの事実が構造化されているため、AIは「エッフェル塔の高さは?」という質問に対して、Webページを探し回るのではなく、データベースから直接「300m」という回答を引き出せます。
RDFによる情報の標準化
Web上の知識をつなげるための共通言語として「RDF(Resource Description Framework)」という規格があります。これは全ての情報を「主語-述語-目的語」の3要素(トリプル)で記述するルールです。
- 主語(Subject)|ボブ
- 述語(Predicate)|知っている
- 目的語(Object)|アリス
このシンプルな形式で記述することで、異なるWebサイトやデータベースの間でも知識を共有・結合できます。まさに世界規模の意味ネットワークといえるでしょう。
大規模言語モデルとの融合
ChatGPTのような大規模言語モデル(LLM)も、広義の意味ネットワークの進化系と捉えられます。ただし、その構造は人間の脳神経に近いニューラルネットワークです。
ChatGPTの裏側にある仕組み
LLMは、膨大なテキストデータから言葉の確率的なつながりを学習しています。これは巨大なベクトル空間の中で、次に来る言葉を予測する「活性化拡散」を行っているようなものです。
従来の知識ベースとは異なり、LLMは知識を「圧縮されたパラメータ」として保持しています。
| 特徴 | 従来の意味ネットワーク(ナレッジグラフ) | 大規模言語モデル(LLM) |
|---|---|---|
| 表現形式 | 記号(ノードとリンク) | ベクトル(数値パラメータ) |
| 強み | 事実の正確さ、説明のしやすさ | 文章作成、翻訳、創造性 |
| 弱み | 柔軟性に欠ける、構築の手間 | 嘘をつくことがある(ハルシネーション) |
| 推論方法 | 論理的なグラフ探索 | 確率的なパターンマッチング |
ニューロシンボリックAIへの期待
現在のAI開発のトレンドは、これら2つのアプローチを融合させる「ニューロシンボリックAI」です。
LLMの流暢な言語能力と、ナレッジグラフの正確な知識構造を組み合わせます。これにより、嘘をつかずに論理的な推論ができ、かつ人間のように自然に話せるAIが実現しようとしています。
「RAG(検索拡張生成)」と呼ばれる技術もその一つです。AIが回答する際に、信頼できる外部のナレッジグラフを参照し、その情報を元に文章を生成します。
まとめ|意味ネットワークはAIの「心」を理解する鍵
意味ネットワークは、単なる技術用語ではなく、知能の本質を突いた概念です。言葉の意味は単独では存在せず、無数のつながりの中に浮かび上がるという事実は、私たち人間の思考そのものを表しています。
- 構造|概念はノード、関係はリンクで表される
- 進化|心理実験を経て、論理的モデルから確率的モデルへ進化した
- 現在|ベクトル空間モデルとナレッジグラフがAIを支えている
私が長年ブログを書いていて感じるのは、良い記事もまた「意味のネットワーク」だということです。一つ一つの情報が適切なリンクでつながったとき、読者の頭の中で深い理解が生まれます。
AIが進化すればするほど、その根底にある「つながりの科学」の重要性は増していくでしょう。この仕組みを知ることは、AIとの対話をより深く楽しむための第一歩なのです。