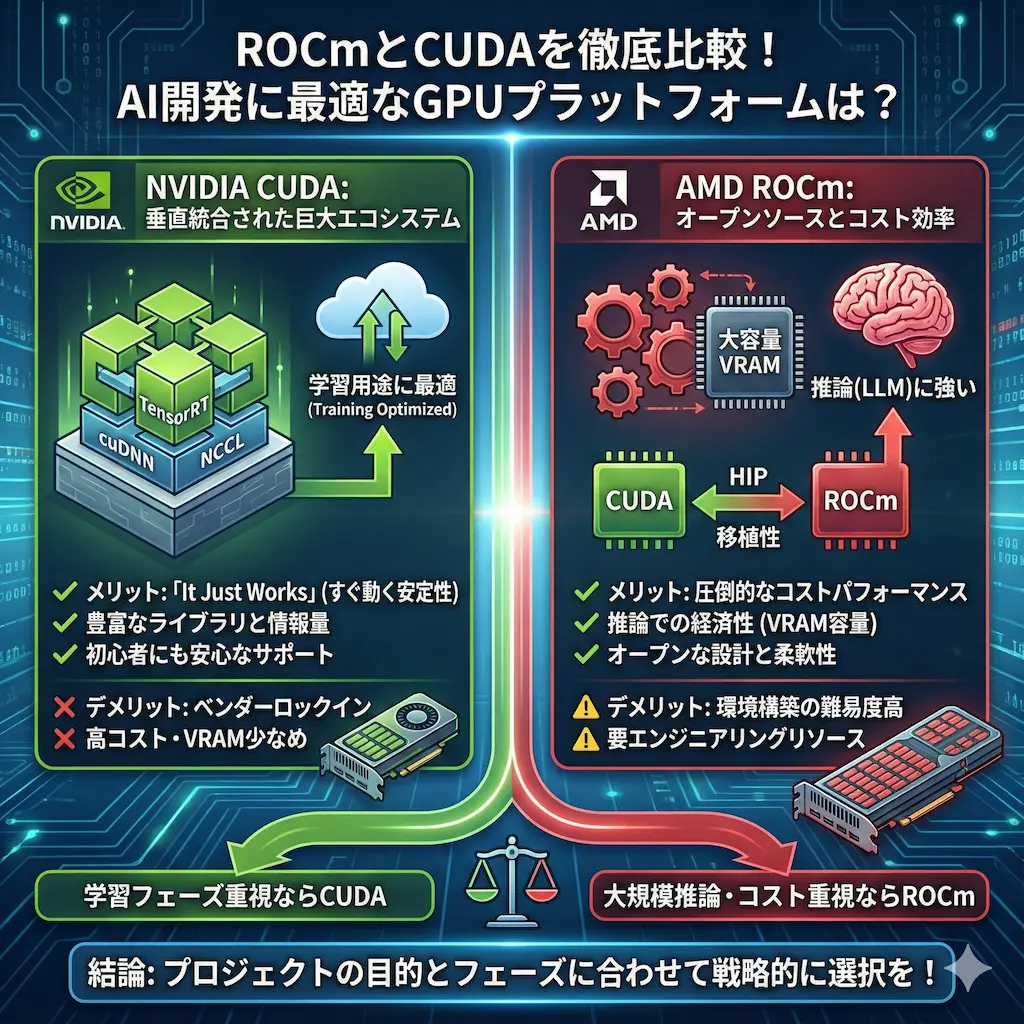
私はAI開発の現場においてGPU選びが最も重要な要素であると考えています。現在はNVIDIAのCUDAとAMDのROCmという二つの巨大な選択肢が並んでいます。
2025年の開発環境ではハードウェアの性能だけではなくソフトウェアの使い勝手が成否を分けます。どちらのプラットフォームが自身のプロジェクトに最適かを見極める必要があります。
CUDAの基本構造と優位性
CUDAはNVIDIAが提供する独自の並列コンピューティングプラットフォームです。AI開発におけるデファクトスタンダードとして長年君臨しています。
私はCUDAが持つ垂直統合のモデルこそが強みであると確信しています。ハードウェアとソフトウェアが完全に同期して設計されているため、性能を極限まで引き出せます。
NVIDIAが構築した並列計算のエコシステム
私はCUDAを単なるツールではなく一つの巨大なエコシステムとして捉えています。2006年の登場以来、膨大な数の開発者がこのプラットフォーム上でコードを蓄積してきました。
ハードウェア側では32個の並列スレッドを「Warp」という単位で管理します。この一貫した実行モデルが開発者に高い予測可能性を提供します。
圧倒的なライブラリ群と信頼性
私はライブラリの充実度がCUDAを選ぶ最大の理由になると考えています。cuDNNやTensorRTといった最適化ライブラリはAIモデルの実行を劇的に加速させます。
多くの新しい論文やAIモデルは、発表初日にCUDA向けのコードが公開されます。最新技術を即座に試したい研究者にとって、CUDA以外の選択肢は考えられません。
ライブラリの具体例
| ライブラリ名 | 用途 |
|---|---|
| cuDNN | 深層学習用のプリミティブ演算 |
| TensorRT | 高性能な推論エンジン |
| NCCL | 複数のGPU間での通信最適化 |
| cuBLAS | 基本的な線形代数演算 |
これらのツールはブラックボックスとして提供されていますが、NVIDIAのエンジニアによって極限までチューニングされています。開発者は低レイヤーの最適化を気にすることなく、モデルの設計に集中できます。
初心者へのサポート体制
私は初心者が最初に触れるべきプラットフォームはCUDAであると断言します。トラブルが発生した際も、インターネット上に解決策が溢れているため独力で解決しやすいです。
ほとんどのクラウドサービスがCUDA環境を標準で提供しています。セットアップの手間が最小限で済む点は、開発スピードを重視するチームにとって大きな魅力です。
CUDAの課題と現状
私はCUDAの唯一にして最大の弱点はベンダーロックインであると考えています。特定のハードウェアに依存するため、NVIDIA製品の高騰がプロジェクトのコストを直撃します。
さらに、VRAM容量あたりの単価がAMD製品に比べて高くなる傾向があります。大規模なモデルを動かす際、ハードウェアの取得コストが大きな壁となります。

ROCmによるAMD GPUの活用
AMDのGPUで深層学習を行うにはROCmプラットフォームを使用します。オープンソースの強みを活かし、急速にその勢力を拡大しています。
私はROCmが「HPCコードはポータブルであるべきだ」という健全な思想に基づいている点を高く評価しています。特定の企業に依存しない開発環境を求める層にとって、強力な選択肢となります。
オープンソースを軸としたROCmの設計
私はROCmのオープンな設計がシステムエンジニアにとって大きな武器になると見ています。コンパイラインフラストラクチャにLLVMを採用しており、スタック全体の中身を確認できます。
深いシステムエンジニアリングが必要なハイパースケーラーにとって、この透明性は不可欠です。特定のワークロードに合わせてカーネルドライバ自体を修正する運用も実現します。
ROCmの主な構成要素
| 構成要素 | 特徴 |
|---|---|
| ROCmランタイム | GPUを制御する基盤ソフトウェア |
| MIOpen | AMD版のcuDNNに相当するライブラリ |
| ROCm Profiler | 詳細なパフォーマンス分析ツール |
| Infinity Fabric | 高速なノード内通信プロトコル |
これらの要素が組み合わさり、高性能な計算環境が構築されます。特にMI300Xのような最新GPUとの組み合わせは、驚異的なスループットを叩き出します。
ハードウェアの特性と Wavefront
AMDのアーキテクチャは伝統的に64スレッドの「Wavefront」を採用しています。これはNVIDIAの32スレッド単位とは異なるため、コードの書き方に注意を払う必要があります。
私はこの設計の違いが特定の演算において高いスループットを生む要因であると考えています。一方で、既存のCUDAコードをそのまま動かす際には微調整が必要です。
HIPによる既存コードの移行プロセス
私はHIPこそがAMDの戦略における要石であると確信しています。HIPはCUDAに近い構文を持つ抽象化層であり、シングルソースでの開発を支援します。
「hipify」という変換ツールを使えば、CUDAコードの大部分を自動でROCm向けに変換できます。9割以上のコードがそのまま移行できるケースも珍しくありません。
移植作業のフロー
自動変換ツールを実行し、ソースコードの記述を置き換えます。その後にハードウェア特有の命令(Intrinsic)を手動で修正する手順を踏みます。
最後にプラットフォーム固有の最適化を施します。手間はかかりますが、一度移植してしまえばNVIDIAとAMDの両方のハードウェアで動作する資産が手に入ります。
アーキテクチャ間の差異への対応
私はWarpサイズの違いに由来する同期処理の修正が最も重要であると考えます。32スレッドを前提としたコードは、64スレッドの環境では正しく動作しない恐れがあります。
こうした課題を乗り越えるためのドキュメントも近年は充実してきました。エンジニアが少しの努力を払えば、AMDの広大なメモリ空間を存分に活用できます。
AI開発における経済性と将来性
私は2025年の開発において、経済的合理性がプラットフォーム選びの決定打になると予測しています。性能あたりのコストにおいて、両者の差は明確になりつつあります。
性能だけを追い求める時代は終わり、投資対効果を最大化する視点が求められています。プロジェクトのフェーズに合わせた最適な投資先を見極める必要があります。
演算性能とVRAM容量の比較
私は大規模言語モデル(LLM)の推論においてAMDが圧倒的な優位性を持っていると評価しています。最新のMI300Xは192GBという膨大なVRAMを搭載しています。
NVIDIAのH100が80GBであることを考えると、一台のGPUに収容できるモデルのサイズに倍以上の開きがあります。これにより、必要なサーバーの台数を劇的に削減できます。
コストパフォーマンスの比較表
| 指標 | NVIDIA H100 | AMD MI300X |
|---|---|---|
| メモリ容量 | 80GB | 192GB |
| メモリ帯域幅 | 3.35 TB/s | 5.3 TB/s |
| 推定取得コスト | 非常に高い | 比較的安価 |
| 入手のしやすさ | 制限あり | 良好 |
私は「トークンあたりのコスト」を計算した際、AMDに軍配が上がる場面が多いと見ています。特に推論に特化したサービスを展開する場合、このコスト差は無視できません。
開発コストとエンジニアリングの負荷
私はハードウェアの安さだけで判断するのは危険であると忠告します。ROCm環境のセットアップやデバッグにかかる人件費も考慮すべきです。
CUDAなら1時間で済む作業が、ROCmでは環境構築に1日かかるケースもあります。小規模なチームであれば、開発速度を優先してNVIDIAを選ぶのが賢明です。
2025年以降のロードマップ
私はPyTorchやTritonといったフレームワークの進化が、両者の溝を埋めていくと考えています。高レベルなライブラリを使えば、背後のGPUが何であるかを意識する必要がなくなります。
AMDはROCm 7.0のリリースにより、ユーザビリティの劇的な向上を狙っています。Windows上でのサポート強化も進んでおり、コンシューマー層の取り込みも加速しています。
将来的な市場予測
私は今後、学習はCUDA、推論はROCmという分業が進むと予想しています。巨大なモデルのトレーニングにはNVIDIAの堅牢なインターコネクト技術が不可欠です。
一方で、コストがシビアに問われる推論サーバーの分野ではAMDがシェアを奪います。この二極化構造が、今後のAIインフラの標準となります。
開発者が今取るべき行動
私は今すぐどちらか一方に賭けるのではなく、ポータブルなコードを書く技術を磨くべきだと考えます。特定のベンダーに依存しないスキルこそが、エンジニアとしての価値を高めます。
PyTorchの抽象化機能を最大限に活用し、プラットフォームを柔軟に切り替えられるように準備してください。ハードウェアの価格変動や供給状況に左右されない強固な体制が構築できます。
まとめ
2025年のAI開発において、CUDAとROCmの選択はプロジェクトの運命を左右します。私は確実な動作と迅速な開発を求めるならCUDA、コスト効率と大規模な推論を重視するならROCmを強く推奨します。
CUDAは洗練された「標準」であり、どのような場面でも期待通りの結果をもたらします。対してROCmは、専門知識を持つエンジニアが使いこなせば、最高の投資対効果を発揮する強力な武器となります。
どちらも一長一短があるため、自身のチームの技術力と予算を冷静に分析してください。適切なプラットフォーム選びが、次世代のAI開発を成功に導く第一歩となります。
今回の比較を参考に、あなたのプロジェクトに最適なGPU環境を構築してください。ご自身の開発環境に合わせて、まずは小規模なインスタンスで両方の動作を試してみるのはいかがでしょうか。