私は2026年現在のローカルLLMシーンにおいて、自宅のPCで巨大なAIを動かす快感に勝るものはないと考えています。プライバシーを守りつつ、クラウド並みの知能を無料で使い倒せる時代がようやく到来しました。
高性能なモデルを動かすにはビデオメモリ(VRAM)の壁が常に立ちはだかります。最新の量子化技術を使いこなすことで、限られたリソースでも驚くほどの推論精度を引き出す知恵を共有します。
世界を席巻する最新グローバルモデルの動向
現在のAI開発は単純な巨大化から効率化へと大きく舵を切りました。私はこの変化こそが、個人のローカル環境を劇的に豊かにした最大の要因だと確信しています。
以前はパラメータ数こそが正義でしたが、今はアーキテクチャの工夫で賢さを維持する手法が主流です。代表的なモデルを把握することで、自分の環境に最適な選択が行えます。
Meta Llama 4が生み出したMoEの衝撃
私は2025年4月に登場したLlama 4ファミリーが、ローカルLLMの常識を根底から覆したと感じています。特に「Scout」と「Maverick」という2つのモデルは、混合専門家(MoE)方式を採用して圧倒的な効率を実現しました。
総パラメータ数が数千億規模であっても、実際に計算で使われるアクティブパラメータはごく一部に抑えられています。これにより、推論速度を保ちながらも数千万トークンという驚異的な文脈理解を達成しました。
1,000万トークンがもたらす革新
Llama 4 Scoutの最大の特徴は、膨大なドキュメントを丸ごと読み込める点にあります。これまでは検索拡張生成(RAG)を組む必要がありましたが、今は全ファイルをプロンプトに流し込むだけで済みます。
私は膨大なコードベースを一気に読み込ませてデバッグを行う際、この広大なコンテキストの恩恵を強く感じています。情報が断片化しないため、論理の破綻が極めて少ない出力が得られます。
ネイティブマルチモーダルの利便性
Llama 4はテキストだけでなく画像も同時に処理する能力を最初から備えています。外部のエンコーダーを介在させないため、画像内の文脈を読み取る精度が格段に向上しました。
私は資料のスクリーンショットを貼り付けてそのまま議論ができる手軽さに、未来のUIを感じています。システム全体がシンプルになり、メモリ消費の無駄も最小限に抑えられています。
Qwen 3とDeepSeek R1による推論能力の民主化
Alibaba Cloudが公開したQwen 3は、コーディングや数学などの論理的思考において頂点に立つモデルです。特に「Thinking Mode」を搭載したことで、人間のように熟考してから回答する挙動を見せます。
一方でDeepSeek R1は、強化学習によって自己進化を遂げた革新的なモデルです。複雑なパズルや競技プログラミングにおいて、プロプライエタリなモデルを凌駕する性能を叩き出しています。
思考プロセスを可視化するメリット
Qwen 3やDeepSeek R1は、回答の前に思考の軌跡をユーザーに提示します。私はこの「考えのプロセス」を見ることで、AIがどこで間違えたかを即座に判断できるようになりました。
熟考させることで、単純な即答では辿り着けない高度な結論へと導くことができます。難しいタスクであればあるほど、この推論特化型モデルの真価が発揮されます。
蒸留モデルによる低スペック環境への対応
DeepSeek R1の優れた推論能力は、より小型のLlamaやQwenモデルへと引き継がれています。これを蒸留と呼び、小さなモデルでも高度な思考ルーチンを実行できるようになりました。
私は7Bや8Bといった軽量モデルでも、論理的な破綻が少ない回答が得られる点に驚いています。限られたVRAM環境のユーザーにとって、蒸留モデルは救世主のような存在です。
日本語特化型モデルの選択肢と現状
日本語の微妙なニュアンスや文化背景を理解させるには、やはり国内で調整されたモデルが最適です。2026年に入り、日本語ベンチマークで圧倒的なスコアを出すモデルが揃いました。
私は日本語モデルの進化によって、仕事での実用性が飛躍的に高まったと実感しています。英語モデルを無理に使うよりも、最初から日本語に最適化されたものを選ぶ方が効率的です。
東京科学大学と産総研によるSwallowの信頼性
Swallowプロジェクトは、Llama 3.1をベースに膨大な日本語データを継続学習させた傑作です。アカデミア主導の開発ならではの透明性の高さと、安定した指示追従能力が魅力です。
日本語特有の敬語表現や慣用句において、他を寄せ付けない自然な文章を生成します。私はビジネス文書の作成や要約において、Swallow 70B Instruct v0.3を最も信頼しています。
英語能力を損なわない継続学習
Swallowの凄みは、日本語を強化しつつも元の英語能力を高く維持している点にあります。日本語と英語が混在する技術ドキュメントの翻訳や解説でも、高い精度を誇ります。
私は論文の解説を依頼する際、このバイリンガルな能力に何度も助けられました。日本語データと英語データを絶妙なバランスで混合学習させた成果が、ここにはっきりと現れています。
指示追従能力の劇的な向上
最新のv0.3アップデートでは、複雑な条件指定に対する忠実度が大幅に強化されました。曖昧な表現を避けて論理的に答えを導き出す力が、Swallowには備わっています。
私は箇条書きや表形式での出力を求める際、Swallowの正確さに絶大な信頼を寄せています。プロンプトエンジニアリングの苦労を最小限にしてくれる、非常に使いやすいモデルです。
楽天AIとELYZAが切り拓く国産LLMの未来
楽天グループが公開したRakuten AI 3.0は、700Bという国内最大級の規模を誇るMoEモデルです。2026年春の公開に向けて期待が高まっており、国内のAI主権を担う存在になると見ています。
またELYZAはQwenをベースにした推論モデルを開発し、論理的思考に強い日本語環境を提供しています。用途に応じてこれらの国産モデルを使い分けるのが、賢い運用術と言えます。
楽天AI 3.0の圧倒的な情報量
楽天の膨大なサービスデータで学習されたこのモデルは、日本の商習慣に極めて精通しています。私はEC関連のトレンド分析やコンテンツ制作において、このモデルが最強のパートナーになると確信しています。
総パラメータ数は巨大ですが、MoEによって推論コストが抑えられている点も魅力的です。ハイエンドなローカル環境であれば、その知能の深さを存分に享受できます。
ELYZAによる思考プロセスの日本語化
ELYZA-Thinkingシリーズは、日本語で「深く考える」ことを追求した特化型モデルです。DeepSeek R1のアプローチを日本語データで再現しており、難解な論理クイズも鮮やかに解き明かします。
私は日本語でのプログラミング解説や、複雑な契約書の解釈にこのモデルを重宝しています。思考プロセスが日本語で出力されるため、納得感のある対話が行えます。
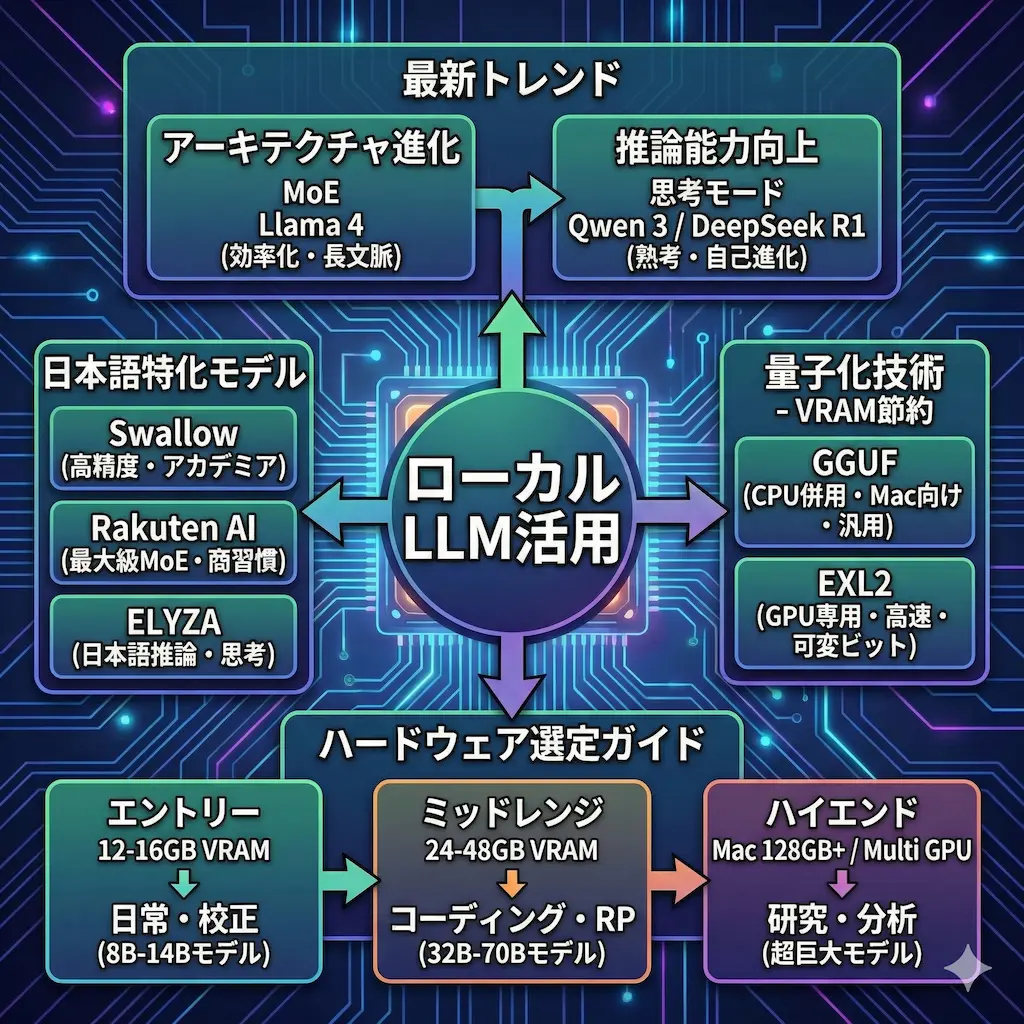
VRAM不足を突破する最新量子化技術
ローカル環境で最大の障害となるVRAM不足は、量子化技術でスマートに解決できます。モデルの重みを圧縮することで、本来は動かないはずの巨大モデルを自分のPCに収める手法です。
私は量子化を「知能のパッキング術」だと考えています。どのフォーマットを選び、どの程度の圧縮をかけるかが、ローカルLLM運用の醍醐味です。
[Image illustrating LLM Quantization concepts like GGUF, EXL2, and weight bit reduction]
GGUF|MacユーザーとCPU併用環境のスタンダード
GGUFはllama.cppをベースとした最も汎用性の高いフォーマットです。最大の特徴は、VRAMに入り切らないデータをPC本体のメインメモリ(RAM)に逃がせる点にあります。
私はApple Siliconを搭載したMacにおいて、このGGUFの恩恵を最大級に受けています。ユニファイドメモリをフル活用することで、巨大なモデルもスムーズに動作させることができます。
メモリオフロードの柔軟性
ビデオメモリが足りない場合でも、GGUFならレイヤー単位でCPU側に処理を割り振れます。速度は多少落ちますが、動かないモデルを動くようにする魔法のような技術です。
私はVRAM 12GBの環境であっても、70Bクラスのモデルを動かすためにこの機能を愛用しています。設定次第で、自分のハードウェアの限界をミリ単位で攻めることができます。
1枚のファイルで完結する手軽さ
GGUFはモデルの重みとメタデータが1つのファイルにまとまっており、管理が非常に楽です。Ollamaなどのツールを使えば、ダウンロードしてすぐにチャットを開始できます。
私は新しいモデルが公開された際、まずはGGUF版を探して動作を確認するようにしています。環境構築の手間がほとんどかからないため、検証作業が非常にスムーズに進みます。
EXL2|NVIDIA GPUで速度と品質を追求する
NVIDIAのGPUを使用しているなら、ExLlamaV2(EXL2)フォーマットが最速の選択肢となります。EXL2は可変ビットレートを採用しており、重要な重みを保護しながら効率的に圧縮します。
私はRTX 3090や4090といったVRAM 24GBクラスのカードを活かすには、EXL2が最適だと感じています。推論速度(トークン生成速度)が他のフォーマットに比べて圧倒的に速いのが特徴です。
2.4bpwから選べる圧縮の多様性
EXL2は、2.4ビットから8ビットまで細かく圧縮率を指定して変換が行えます。VRAMの空き容量に合わせて、モデルの賢さを最大限に残したままパッキングすることが可能です。
私はVRAMが数GB足りないといった際、少しだけビットレートを下げて収めるテクニックを多用しています。4ビット相当の画一的な圧縮よりも、精度を維持しやすいのが強みです。
マルチGPU環境での高い効率
複数のGPUを搭載している場合、EXL2はビデオメモリ間の負荷分散が非常に優秀です。バス帯域を有効に使い、大規模なモデルでもストレスのないレスポンスを実現します。
私は2枚のGPUを連結して動かす際、その生成速度の速さにいつも驚かされています。リアルタイムでのチャットや執筆支援において、このスピードは大きな武器になります。
目的に合わせたハードウェアとモデルの選定ガイド
最新の技術を反映させた、2026年版の推奨構成を整理しました。自分の予算と目的に合わせて、後悔のないパーツ選びとモデル選びを行ってください。
私は無理に最高峰を目指すよりも、自分の活動スタイルに合った「バランス」を重視すべきだと考えています。以下の表を参考に、最適な組み合わせを見つけてください。
| クラス | 推奨ハードウェア | 最適なモデル例 | 主な用途 |
|---|---|---|---|
| エントリー | VRAM 12GB – 16GB | Llama 4 Scout (Small), Swallow 8B | 日常対話・文章校正 |
| ミッドレンジ | VRAM 24GB – 48GB | Qwen 2.5 32B, DeepSeek-R1-Distill-70B | 高度なコーディング・RP |
| ハイエンド | Mac 128GB+ / Multi GPU | Llama 4 Maverick, Rakuten AI 3.0 | 研究開発・大規模データ分析 |
24GB VRAM環境を使い倒すコツ
ミッドレンジの王道であるRTX 3090や4090(VRAM 24GB)は、ローカルLLMユーザーの聖地です。この環境なら、中規模モデルを最高品質で動かすことも、大規模モデルを量子化して動かすことも選べます。
私はEXL2の4.0bpw前後で70Bクラスのモデルを動かすのが、知能と速度のベストバランスだと感じています。この構成さえあれば、大抵のタスクをストレスなくこなすことができます。
Mac Studioによる超巨大モデルの運用
Apple SiliconのMac Studio(192GBメモリ構成)は、もはや個人のスーパーコンピュータです。Llama 4 Maverickや405Bクラスの超弩級モデルを、量子化版でゆったりと動作させられます。
私は省電力で静音、かつ膨大なメモリを使えるMacの環境に深い愛着を持っています。速度よりも「全ての知識を手元に置く」というロマンを追い求めるなら、Macこそが正解です。
まとめ
2026年のローカルLLM環境は、MoEアーキテクチャと洗練された量子化技術によって黄金期を迎えました。ビデオメモリの制約を技術で乗り越え、誰でも高度なAI知能を手に入れられるようになっています。
私は日々進化するこれらのツールを使い倒すことで、個人の生産性が何倍にも膨れ上がると確信しています。まずは手元の環境で、自分だけの「賢い相棒」を育ててみてください。