機械学習の決定木アルゴリズムにおいて、最も重要な役割を果たすのが「どのようにデータを分割するか」という判断基準です。私が多くのプロジェクトで経験してきた中で、最も頻繁に使用され、かつ信頼性が高い指標が「ジニ不純度(Gini Impurity)」といえます。
本記事では、このジニ不純度が具体的に何を意味するのか、どのように計算されるのかを、初心者の方にも直感的にわかるように解説します。Scikit-Learnなどのライブラリを使う際、デフォルト設定の意味を正しく理解することは、エンジニアとしてのスキルアップに直結します。
機械学習におけるジニ不純度の基本概念
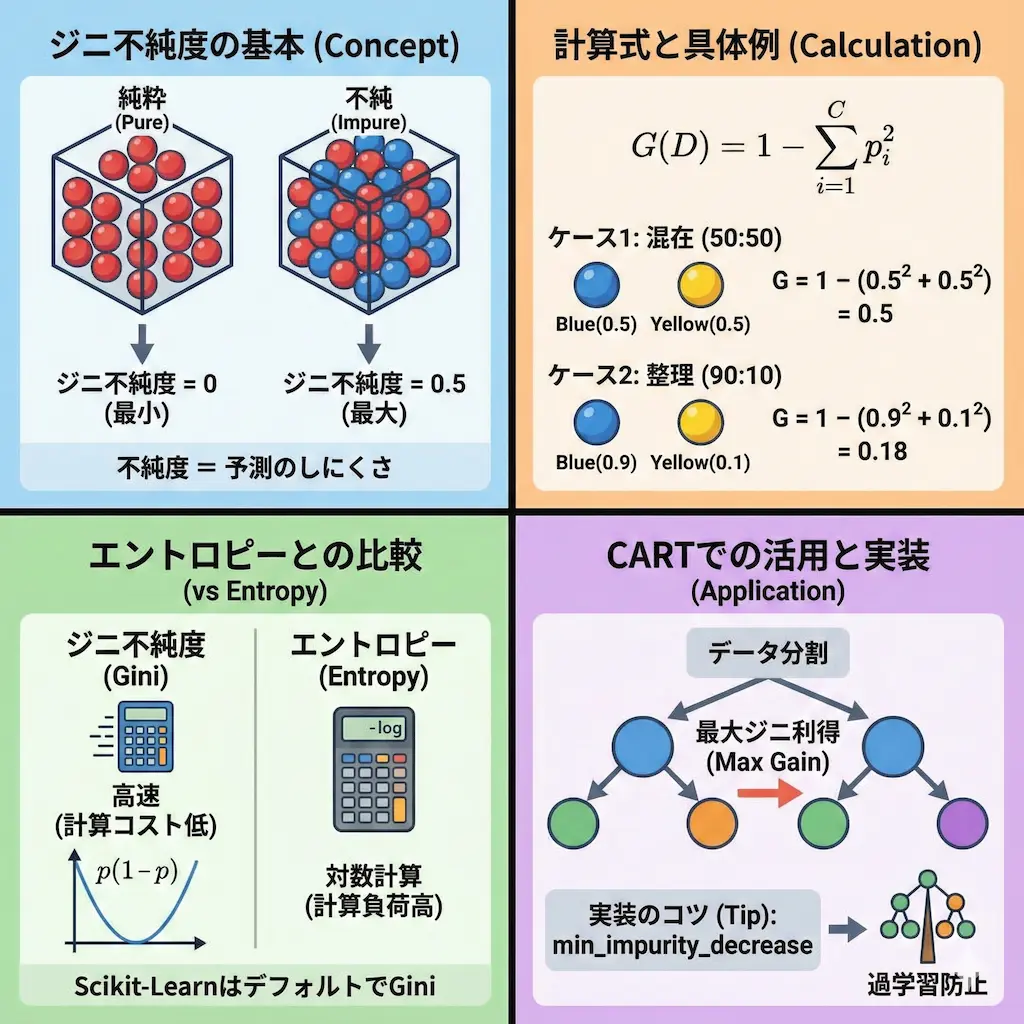
ジニ不純度とは、一言で言えば「データセットの中にどれだけ異質なものが混ざっているか」を表す指標です。
分類問題において、あるノード(データの集合)が単一のクラスだけで構成されているのか、それとも複数のクラスが混在しているのかを数値化します。
不純度という言葉が持つ本当の意味
「不純度」という言葉を聞くと難しく感じるかもしれませんが、イメージは非常にシンプルです。
箱の中に「赤色のボール」だけが入っていれば、その箱は「純粋」であり、不純度は0になります。
一方で、赤と青のボールが半分ずつ混ざっていれば、どちらを取り出すか予測がつかないため、不純度は高くなります。
私が初心者に説明する際は、「不純度=予測のしにくさ」と言い換えることが多いです。
決定木はこの不純度をゼロに近づけるように、データの分割を繰り返していくアルゴリズムといえます。
経済学のジニ係数との関係性と違い
「ジニ」という名前を聞いて、経済学の所得格差を表す「ジニ係数」を思い浮かべる方もいるでしょう。
実はどちらもイタリアの統計学者コッラド・ジニに由来しており、分布の偏りを測るという根本的なアイデアは共通しています。
しかし、計算式や適用範囲は厳密には異なります。
機械学習におけるジニ不純度は、分類ミスが発生する確率に基づいた指標として設計されています。
あくまで「クラス分類の混ざり具合」を評価するためのツールであると認識してください。
値の範囲と確率論的な解釈について
ジニ不純度が取りうる値の範囲を知っておくことは、モデルの挙動を理解する上で重要です。
2クラス分類(例:YesかNoか)の場合、ジニ不純度は「0から0.5」の範囲に収まります。
- 0の場合|完全に分類ができている状態(純粋)
- 0.5の場合|クラスが完全に半々に混ざっている状態(最も不純)
多クラス分類の場合は、クラス数が増えるにつれて最大値が1.0に近づいていきます。
この数値は、「その集合からランダムに1つデータを選び、クラス分布に従ってランダムにラベルを付けたとき、間違える確率」と解釈できます。
ジニ不純度の計算式と具体的な導出プロセス
概念を理解したところで、次は具体的な計算方法を見ていきましょう。
数式は非常にシンプルで、手計算でも十分に確認できます。
定義式をわかりやすく分解する
データセット D に C 個のクラスがあり、各クラス i の出現確率を pi とします。
このとき、ジニ不純度 G(D) は以下の式で定義されます。
$$G(D) = 1 – \sum_{i=1}^{C} p_i^2$$
この式が意味するのは、「全事象の確率(1)から、正解する確率(各クラス確率の二乗和)を引く」ということです。
pi^2 は、あるクラス i のデータを選び、かつ正しくクラス i とラベル付けする確率を表します。
つまり、正解率を1から引くことで、誤分類率(=不純度)を求めているわけです。
具体的な数値を使った計算シミュレーション
数式だけではイメージしにくいので、具体的な例で計算してみます。箱の中にボールが20個あり、青が10個、黄色が10個入っている状態を想像してください。
ケース1:完全に混ざっている場合
青の確率は 0.5、黄色の確率も 0.5 です。
$$G = 1 – (0.5^2 + 0.5^2) = 1 – (0.25 + 0.25) = 1 – 0.5 = 0.5$$
これが2クラス分類における最大値となります。
ケース2:少し整理された場合
次に、青が18個、黄色が2個の状態を計算します。
青の確率は 0.9、黄色の確率は 0.1 です。
$$G = 1 – (0.9^2 + 0.1^2) = 1 – (0.81 + 0.01) = 1 – 0.82 = 0.18$$
不純度が0.5から0.18に下がり、純度が高まったことがわかります。
グラフで見る放物線の形状と特性
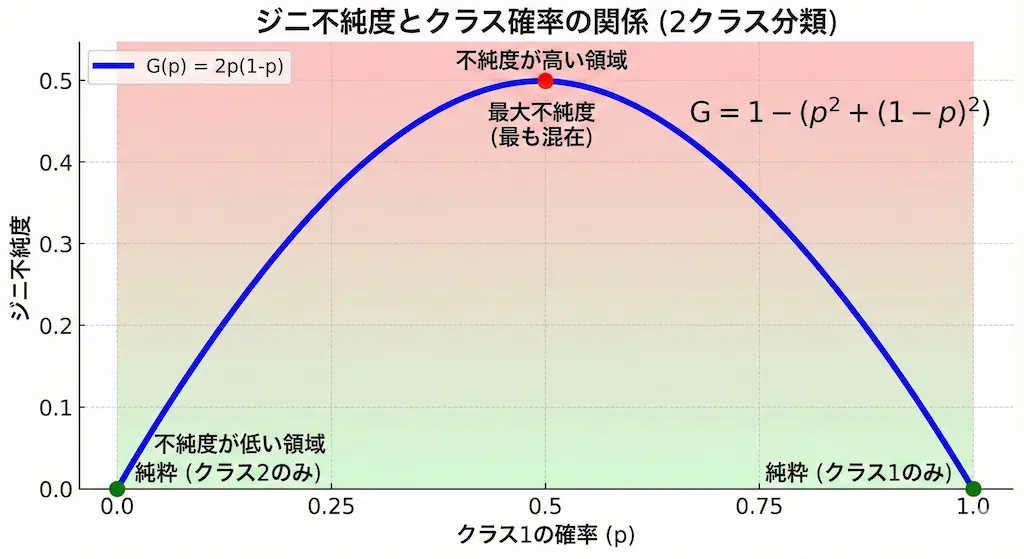
横軸にクラス1の確率 p をとり、縦軸にジニ不純度をとると、そのグラフは美しい放物線(二次関数)を描きます。
p=0 と p=1 のときに値は0になり、p=0.5 で頂点の0.5になります。
この「滑らかな放物線」であるという特性が、コンピュータにとって非常に都合が良い点です。
計算が単純であり、かつ微分可能であるため、最適解を見つけるための計算コストが低く抑えられます。
エントロピーとの違いと使い分けのポイント
決定木を学ぶ際、必ずと言っていいほど比較されるのが「エントロピー(情報利得)」です。
「どちらを使うべきか」という疑問に対し、私は明確な基準を持っています。
計算コストと処理速度の比較結果
エントロピーの計算式には、対数(log)が含まれています。
一方で、ジニ不純度は四則演算(二乗と引き算)のみで計算できます。
コンピュータにおいて、対数計算は単純な掛け算よりも処理負荷が高いです。
ランダムフォレストのように何千本もの木を作る場合、このわずかな差が積み重なって学習時間に影響します。
そのため、計算速度を重視するならばジニ不純度の方が有利です。
分類精度における実質的な差はあるか
多くの研究結果が示している通り、分類精度において両者に大きな差が出ることは稀です。
統計的には、98%以上のケースで両者は同じような決定木を作成します。
実務において、この2つの指標の違いがプロジェクトの成否を分けることはほぼありません。
私は、特別な理由がない限り、計算が高速なジニ不純度を優先して使用しています。
Scikit-Learnでデフォルト採用される理由
Pythonの代表的な機械学習ライブラリであるScikit-Learnでは、決定木のパラメータ criterion のデフォルト値は 'gini' です。
これは前述した「計算効率の良さ」が主な理由です。
エントロピーを使いたい場合は明示的に指定する必要がありますが、通常はデフォルトのままで問題ありません。
エンジニアは、デフォルトが選ばれている背景にある「計算コストへの配慮」を理解しておくべきです。
CARTアルゴリズムでの動作と実装のコツ
ジニ不純度は、CART(Classification and Regression Trees)というアルゴリズムの中核を担っています。
実際にどのようにデータが分割されるのか、そのメカニズムを解説します。
ジニ利得を最大化する分割の仕組み
CARTアルゴリズムは、あらゆる特徴量と閾値を試し、「分割後の不純度が最も低くなる点」を探します。
このとき、「分割前の不純度」と「分割後の不純度の加重平均」の差を「ジニ利得(Gini Gain)」と呼びます。
アルゴリズムは単純に、このジニ利得が最大になる分割ルールを採用します。
これを繰り返すことで、データは徐々に純粋なグループへと整理されていきます。
私がコードを書くときは意識しませんが、裏側ではこのような泥臭い探索が行われているのです。
Scikit-Learnでのパラメータ設定と注意点
実装時には、ジニ不純度に関連するいくつかのパラメータを調整することで、モデルの性能をコントロールできます。
特に min_impurity_decrease は有用です。
これは「不純度がこれ以上減らないなら分割をやめる」という閾値を設定するものです。
この値を適切に設定することで、データの細かすぎるノイズに反応して木が複雑になりすぎる「過学習」を防げます。
単に精度を追うだけでなく、汎用性のあるモデルを作るためには必須の知識です。
まとめ|ジニ不純度を理解してモデル構築に活かす
ジニ不純度は、決定木がデータを分類するための最も基本的かつ強力な羅針盤です。
確率論に基づいた「誤分類のしやすさ」を表す指標であり、その計算の軽さから現代の機械学習のスタンダードとなっています。
エントロピーとの違いに悩みすぎる必要はありません。
まずはジニ不純度の「値が低いほど純粋である」という性質と、それがどのように分割に使われるかという仕組みを確実に押さえてください。
この基礎理解があれば、パラメータチューニングの際にも、なぜモデルがそのような挙動をするのかが手に取るようにわかるようになります。
ぜひ、実際のデータ分析の現場で、この指標の挙動を確認してみてください。