私はこれまで数多くのIT資格や技術トレンドを分析してきましたが、今回のG検定(ジェネラリスト検定)の改定は過去最大級のインパクトがあります。2017年の創設以来、AIリテラシーの基準として機能してきた本検定が、2024年11月実施の試験より劇的に生まれ変わりました。
今回の改定の核心は「AIを作る」知識から「AIを使いこなし、統制する」知恵への重心移動です。ChatGPTに代表される生成AIの爆発的な普及を受け、私たちは技術的な仕組みだけでなく、法的・倫理的な判断力を問われる時代に突入しました。本記事では、この大幅なシラバス変更の全容と対策を徹底的に解説します。
2024年改定の背景と狙い
JDLA(日本ディープラーニング協会)が主催するG検定は、AI活用能力を測る国内最高峰の資格です。
これまでのG検定は、ニューラルネットワークの基礎や機械学習アルゴリズムを理解し、エンジニアと対話できる人材の育成に主眼を置いていました。しかし、2022年後半からの生成AIブームにより、状況は一変しました。
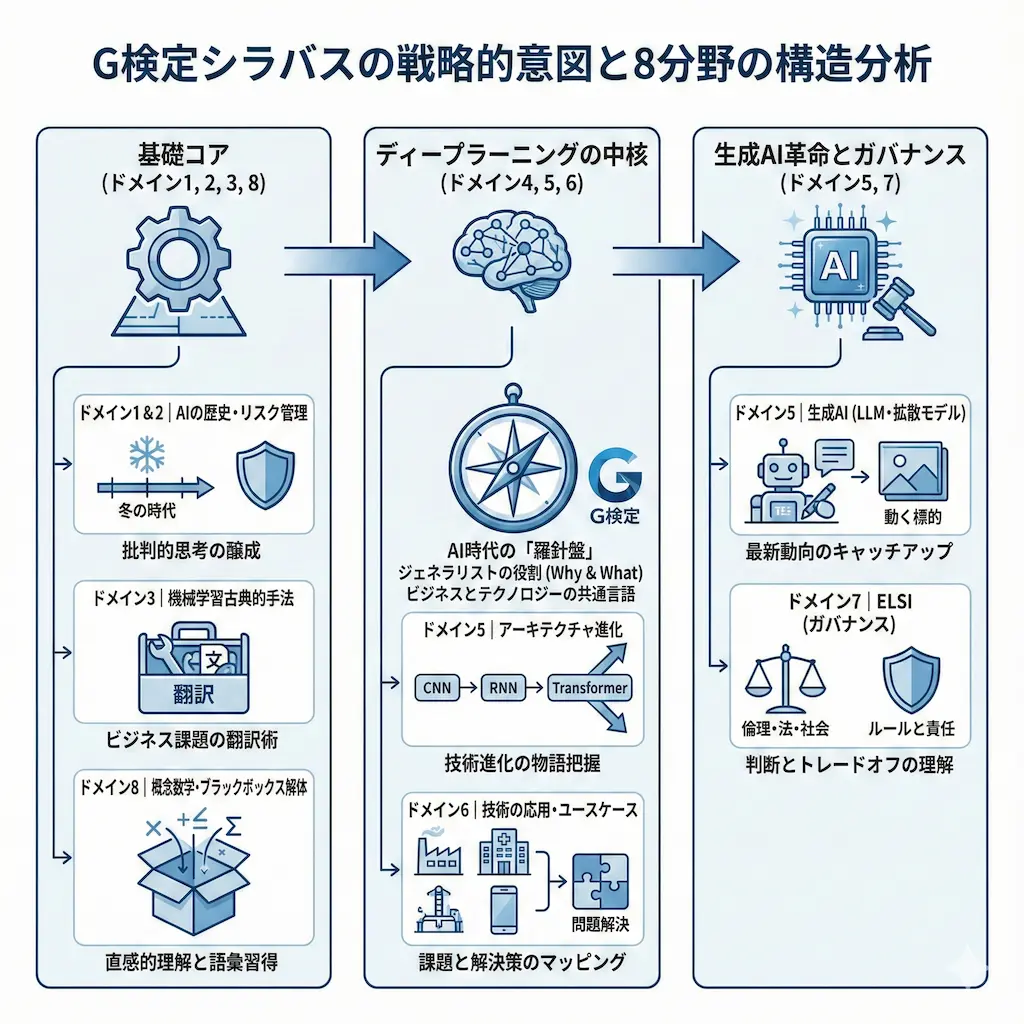
新シラバス|8分野の学習ロードマップ
シラバスの8分野は、知識ゼロからでもAIの全体像を掴めるように、論理的な順序で構成されています。
- 一般(ドメイン1, 2)| AIの定義や歴史的背景を理解します。
- 特定(ドメイン3)| AIの中核技術である「機械学習」の古典的な手法を学びます。
- 深層(ドメイン4, 5)| 現代AIの「ディープラーニング」の理論と高度な手法を学びます。
- 応用(ドメイン6)| これらの技術が現実のビジネスでどう使われているかを学びます。
- 統治(ドメイン7)| AIを社会で使う上での「ルールと責任(ELSI)」を学びます。
- 基盤(ドメイン8)| これら全てを支える「概念的な数学」を理解します。
この流れは、まさに「理論から実践、そしてガバナンスへ」という、ジェネラリストに必要な思考の道筋そのものです。
| ドメイン1 人工知能とは | 人工知能の定義 人工知能研究の歴史 |
| ドメイン2 人工知能をめぐる動向 | 探索・推論 知識表現 機械学習、深層学習 |
| ドメイン3 人工知能分野の問題 | トイプロブレム フレーム問題 弱いAI、強いAI 身体性 シンボルグラウンディング問題 特徴量設計 チューリングテスト シンギュラリティ |
| ドメイン4 機械学習の具体的手法 | 教師あり学習 教師なし学習 強化学習 モデルの評価 |
| ドメイン5 ディープラーニングの概要 | ニューラルネットワークとディープラーニング ディープラーニングのアプローチ ディープラーニングを実現するには 活性化関数 学習率の最適化 更なるテクニック |
| ドメイン6 ディープラーニングの手法 | 畳み込みニューラルネットワーク(CNN) 深層生成モデル 画像認識分野 音声処理と自然言語処理分野 深層強化学習分野 モデルの解釈性とその対応 モデルの軽量化 |
| ドメイン7 ディープラーニングの社会実装に向けて | AIと社会 AIプロジェクトの進め方 データの収集 データの加工・分析・学習 実装・運用・評価 クライシス・マネジメント |
| ドメイン8 数理・統計 |
「構築」から「活用・統制」へのパラダイムシフト
高度なプログラミングスキルを持たない一般ユーザーでも、自然言語で最先端AIを操作できる時代が到来しました。この環境変化に伴い、G検定が認定すべき能力は大きく拡張されました。これまでは「どう作るか(Making)」が中心でしたが、これからは「どう使い(Using)、どうリスクを管理するか(Governing)」という実践的リテラシーが求められます。
JDLAはこの変化に対応するため、生成AI関連技術や最新の法規制を大幅に拡充しました。これは単なる知識のアップデートではなく、AIジェネラリストという定義そのものの再構築です。受験者は技術知識に加え、ビジネス現場での判断力を養う必要があります。
生成AI時代に求められる新たなスキルセット
今回の改定は2024年11月8日・9日実施の「G検定2024 #6」から適用されます。これに伴い、公式テキストも第3版へと刷新されました。これから受験する方は、旧来の知識体系に加え、プロンプトエンジニアリングやAIガバナンスといった新領域の習得が必須です。
単にツールの名前を覚えるだけでは通用しません。AIがもたらす社会的影響や、法的リスクを深く理解することが求められます。次の章からは、具体的な変更点を技術と法務の両面から深掘りします。
生成AIと技術分野の刷新
本改定の最大の目玉は、生成AI関連項目の大幅な拡充です。従来の「ディープラーニングの応用」という枠組みが再編され、LLM(大規模言語モデル)を中心とした現代的な技術体系へとアップデートされました。
大規模言語モデル(LLM)と基盤モデルの理解
AI開発のアプローチは、特定のタスク専用モデルを一から作る手法から、巨大な「基盤モデル」を利用する手法へと転換しました。この変化を理解するために、以下のキーワードを押さえる必要があります。
トランスフォーマー(Transformer)|BERTやGPTシリーズの基盤となるアーキテクチャです。Attention機構を用いることで、並列処理と長距離依存関係の学習を実現しました。Self-Attentionの計算メカニズムや、Encoder-Decoder構造の役割分担は頻出ポイントといえます。
スケーリング則(Scaling Laws)|モデルのパラメータ数やデータセットのサイズが増えるにつれ、性能が予測可能な形で向上する法則です。これが現在の大規模開発競争の理論的支柱となっています。
創発的特性(Emergent Capabilities)|ある規模を超えたモデルにおいて、学習時には意図されていなかった能力が突如として発現する現象です。算術演算や推論能力などがこれに該当します。
プロンプトエンジニアリングの実践的技術
「プロンプトエンジニアリング」が正式な試験範囲に含まれた点は非常に重要です。プロンプトは単なる命令文ではなく、モデルの内部状態を誘導するための技術的インターフェースだからです。
Zero-shot / Few-shot Learning|モデルに追加学習を行わせることなく、プロンプト内に例示を含めるだけでタスクを遂行させる手法です。これを「文脈内学習(In-Context Learning)」と呼びます。
Chain-of-Thought (CoT)|「ステップバイステップで考えて」という指示を与えることで、モデルに推論過程を出力させる手法です。これにより、複雑な問題の正答率が劇的に向上します。
RAG (Retrieval-Augmented Generation)|外部データベースから関連情報を検索し、プロンプトに組み込む技術です。ハルシネーション(もっともらしい嘘)を抑制し、最新情報に対応させるために不可欠なアーキテクチャです。
マルチモーダルとデータ生成技術
画像生成AIの普及に伴い、テキストと画像を相互に変換する技術もシラバスに追加されました。Stable Diffusionなどで使われる「拡散モデル(Diffusion Models)」や、画像とテキストの関係を学習する「CLIP」は必須知識です。
また、AIの学習データ不足を補う「合成データ(Synthetic Data)」の重要性も高まっています。プライバシー保護のためのダミーデータ生成など、データを「集める」から「作る」時代への変化を認識しましょう。
古典的AIと歴史的背景の再評価
最新技術だけでなく、「古典的AI」に関する記述が強化された点も見逃せません。現在のLLMが持つ推論能力を、過去の記号主義的アプローチと比較・相対化するためです。
SHRDLU(シュルドル)|1970年に開発された自然言語理解プログラムです。「積み木の世界」という限定空間内でユーザーの指示を理解しました。現代のLLMとの対比において重要なマイルストーンです。
STRIPS|自動計画(プランニング)システムの草分けです。前提条件と効果を記述して行動計画を生成する論理構造は、現在のAIエージェントの基礎として参照されます。
これらを知ることで、現在のAIが何を得意とし、何を苦手としているのかがより鮮明に見えてきます。「AI効果」という概念も合わせ、技術の進化を俯瞰する視点を持ってください。
法務・倫理とガバナンスの強化
G検定2024年シラバスにおいて、最も実務的かつ重要な拡張が行われたのが法律・倫理分野です。日本は世界的に見てもAI開発に有利な著作権法制を持っています。この法的アドバンテージを正しく理解し活用することは、日本のAI人材にとって必須の能力です。
著作権法第30条の4とAI開発
日本の著作権法第30条の4は、世界でも稀に見る「機械学習フレンドリー」な条項です。この条項の解釈と適用範囲について、正確な理解が求められます。
権利制限規定|「著作物に表現された思想又は感情の享受を目的としない」場合、原則として著作権者の許諾なく著作物を利用できます。これはAIの学習(情報解析)を強力に後押しする規定です。
ただし、「著作権者の利益を不当に害する場合」は例外となります。生成AIが特定のクリエイターの画風を模倣して市場を奪うようなケースにおいて、この例外規定がどう解釈されるかが現在の重要な論点です。
AI生成物の著作権と契約実務
「AIが作った作品に著作権は発生するか」という問いに対し、シラバスは明確な判断基準を提示しています。ポイントは「創作的寄与」の有無です。
人間がAIを単なる道具として使い、詳細な指示や修正を加えた場合にのみ、人間に著作権が発生する可能性があります。AIが自律的に生成しただけのものは、著作物とは認められないというのが現在の通説です。
また、ビジネス現場での契約形態についても知識が問われます。
請負契約|仕事の完成を約束し、瑕疵担保責任を負います。
準委任契約|業務の遂行を約束し、善管注意義務を負います。探索的なAI開発ではこちらが一般的です。
セキュリティと新たなリスク
AI特有の脆弱性への対応として、「セキュリティ」の項目が追加されました。従来のサイバー攻撃とは異なる、AIならではの攻撃手法を理解する必要があります。
敵対的攻撃(Adversarial Attacks)|画像に微細なノイズを加えてAIの誤認識を誘発する攻撃です。
プロンプトインジェクション|LLMに特殊な命令を入力し、安全装置(ガードレール)を回避して不適切な出力を引き出す攻撃です。
これらは開発者だけでなく、AIを利用するすべてのユーザーが知っておくべきリスクです。
まとめ:AIガバナンスの担い手へ
2024年のG検定シラバス改定は、単なる試験範囲の変更ではありません。これは、AIに関わるすべての人材に対する「意識改革」の要請です。これからのジェネラリストは、データサイエンティストと話せるだけの翻訳者ではなく、AIという強力なツールを組織の目標達成のために導く「指揮者」となる必要があります。
今回の改定で追加された内容は、実務において直面する課題そのものです。「自社データをChatGPTに入力して良いか」「生成した画像を広告に使って良いか」。こうした問いに即座に答えられる能力こそが、今求められています。
G検定の合格者は、組織における「AIガバナンスの担い手」として機能することが期待されます。技術の進化と社会のルール、その両方をバランスよく理解し、AIの社会実装を推進していきましょう。