現代社会において、データはビジネスや意思決定の羅針盤です。しかし、目の前にあるデータが本当に全体を反映しているのか不安になることはありませんか。
膨大なデータの中から真実を見つけ出すためには、統計学の基礎概念である「母集団」と「標本」の理解が欠かせません。私は長年の経験から、この二つの関係性を正しく把握することこそが、データ分析の成功への近道だと確信しています。
本記事では、難解な数式をなるべく使わず、母集団と標本の違いから実践的なデータ収集のルールまでをわかりやすく解説します。
統計学の基礎となる母集団と標本の定義|正しい理解がスタートライン
データ分析を始めるにあたり、まずは対象となる領域を明確にする必要があります。ここでは、統計学の最も基本的な概念である母集団と標本について、その定義と役割を解説します。
母集団とは何か|調査対象となるすべての集合体
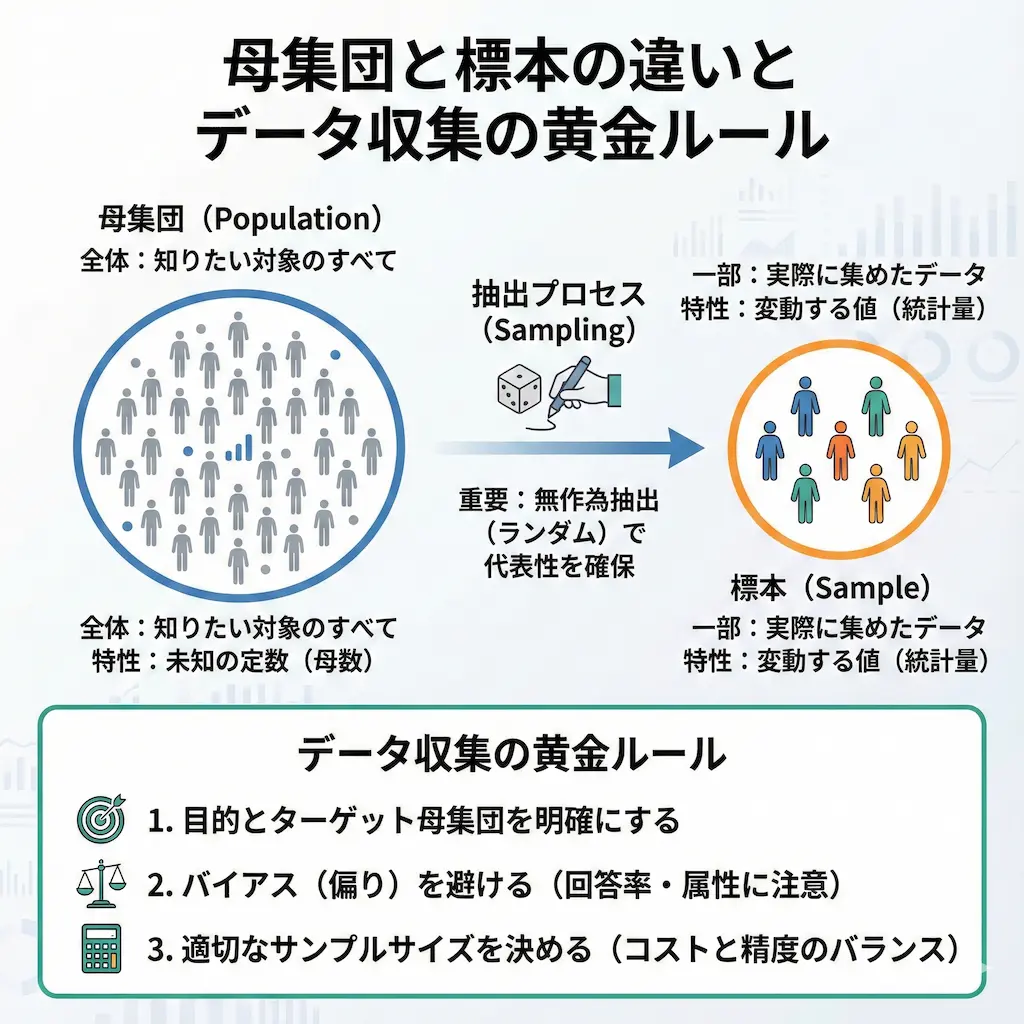
母集団とは、あなたが知りたいと思っている対象の「すべて」を含むグループのことです。これは調査や分析のゴールであり、ここに潜む真実を解き明かすことが最終的な目的となります。
例えば、日本人全体の平均身長を知りたい場合、今の日本に住むすべての人々が母集団です。工場の品質管理であれば、そのラインから生産されるすべての製品が母集団に該当します。
母集団には、物理的に存在する集団だけでなく、将来生産される製品のような概念的な集団も含まれます。ここを定義し損ねると、すべての分析が無意味になってしまいます。
目標母集団と調査母集団のズレ
母集団を定義する際、理想とする「目標母集団」と、実際にリスト化できる「調査母集団」には乖離が生じることがあります。例えば、全有権者を対象にしたくても、電話番号リストには電話を持っていない人が含まれません。
このズレは「カバレッジ誤差」と呼ばれ、調査結果に歪みをもたらす主要な原因です。私は、調査設計の段階でこのズレをどこまで許容できるか確認することをおすすめします。
有限母集団と無限母集団
母集団はその要素の数によって、有限母集団と無限母集団に分けられます。有限母集団は「ある学校の全校生徒」のように数が数えられるものです。
一方、無限母集団は「サイコロを振り続けた出る目」のように、無限にデータが生成されるものを指します。実務では数が十分に大きい有限母集団を、計算を簡単にするために無限母集団として扱うケースが多くあります。
標本とは何か|母集団から選び出された一部のデータ
標本(サンプル)とは、母集団の性質を知るために抽出された一部のデータの集まりです。全数調査が物理的、経済的に難しい場合、この標本を使って全体を推測します。
標本調査で最も重要なのは、その標本が母集団の縮図になっているかどうかという「代表性」です。どんなに大量のデータを集めても、偏った標本からは誤った結論しか導き出せません。
良い標本と悪い標本
良い標本とは、母集団の特性を偏りなく反映しているものです。逆に悪い標本とは、特定の属性に偏りがあるものを指します。
例えば、国民の健康意識を調べるのに、スポーツジムの前だけでアンケートをとれば結果は偏ります。これは典型的な「選択バイアス」であり、避けるべき失敗例です。
全数調査と標本調査の使い分け|コストと精度のバランス
全数調査は母集団すべてを調べるため、誤差のない正確な事実が得られます。国勢調査などがこれに該当しますが、膨大なコストと時間がかかります。
対して標本調査は、一部を調べるだけで済むため、低コストかつ迅速に結果を得られます。現代のマーケティングや世論調査のほとんどは、効率性を重視して標本調査を採用しています。
データの信頼性を左右する抽出のメカニズム|ランダム性が命
母集団と標本の関係を理解した次は、実際にどのようにデータを抽出するかという技術論になります。ここでは、統計的な正当性を保つための抽出ルールを解説します。
母数と統計量の違い|定数と変数を区別する
統計学では、母集団の真の値を「母数」、標本から計算された値を「統計量」と呼び、厳密に区別します。この違いを理解することは、データ分析のリテラシーを高める上で不可欠です。
母数は神のみぞ知る「定数」であり、変化することはありません。一方で統計量は、選ばれた標本によって毎回値が変わる「確率変数」です。
以下の表に、それぞれの代表的な指標と言葉の定義を整理しました。
| 項目 | 母集団 (Population) | 標本 (Sample) |
|---|---|---|
| 指標の呼び名 | 母数 (Parameter) | 統計量 (Statistic) |
| 性質 | 未知の定数 (固定値) | 確率変数 (変動する値) |
| 要素数 | N | $n$ |
| 平均 | 母平均 (μ) | 標本平均 (x) |
| 分散 | 母分散 (σ^2) | 標本分散 (s^2) |
無作為抽出の重要性|恣意性を排除する
標本が母集団を代表するためには、人間の主観が入らない「無作為抽出(ランダムサンプリング)」を行う必要があります。これが守られていないデータは、統計的な推測の土台に乗せることができません。
無作為抽出とは、母集団のすべての要素が選ばれる確率が等しい状態を作る操作です。くじ引きや乱数表を使うことで、意図しない偏りを排除します。
層化抽出法による精度向上
無作為抽出をより効率的に行う手法として、層化抽出法があります。これは母集団を年代や地域などのグループ(層)に分け、各層から無作為に抽出する方法です。
例えば選挙の出口調査では、都市部や農村部といった地域特性ごとに層を分けます。これにより、単なるランダム抽出よりも少ないサンプル数で、全体の傾向を正確に捉えることができます。
標本誤差とサンプルサイズの決定|数は力なり
標本調査には必ず誤差が伴いますが、サンプルサイズを増やすことでその誤差を小さくできます。統計学には「中心極限定理」という強力な法則があり、サンプル数が増えれば平均値の分布は安定します。
一般的に、信頼度95%で調査を行う場合、許容できる誤差範囲から逆算して必要なサンプル数を決定します。例えば、視聴率調査などで誤差を数パーセントに抑えるには、数千ではなく数百から数千程度のサンプルで十分なケースが多いです。
n=600 の持つ意味
テレビの視聴率調査などで、サンプル数が600世帯程度に設定されているのを見たことがあるかもしれません。統計的に計算すると、サンプルサイズが600あれば、誤差はおよそ $\pm 4\%$ 程度に収まります。
これは、もし視聴率が15%と出た場合、真の値は高い確率で11%から19%の間にあることを意味します。ビジネス判断において、この精度で十分であれば、それ以上のコストをかける必要はありません。
実践で役立つデータ収集の黄金ルール|失敗しないためのポイント
理論を踏まえた上で、明日からの実務に使える具体的なアクションプランを提示します。信頼できるデータを集めるための黄金ルールは以下の通りです。
目的を明確にしてターゲット母集団を定義する
データ収集を始める前に、「誰のことを知りたいのか」を言語化してください。ここがブレていると、どれだけ高度な分析を行っても意味のある答えは出ません。
例えば、新商品の満足度を知りたい場合、対象は「購入者全員」なのか「リピーター」なのかで調査設計は変わります。母集団の定義は、具体的であればあるほど、得られるインサイトは鋭くなります。
バイアスの罠を避ける|回答率と属性の偏りに注意
現代の調査において最大の敵は、サンプル数の不足ではなく「バイアス(偏り)」です。特に、特定の意見を持つ人だけが回答する「非回答バイアス」には警戒が必要です。
Webアンケートなどで極端に回答率が低い場合、その結果はサイレントマジョリティの意見を反映していないと考えるべきです。私は、結果の数字を鵜呑みにせず、どのような人々が回答しなかったかを想像することを強く推奨します。
適切なサンプルサイズを見積もる|コストと精度のバランス
やみくもにデータを集めるのではなく、必要な精度(許容誤差)を決めてからサンプル数を算出してください。無限母集団を想定した場合、信頼度95%・許容誤差5%であれば、必要なサンプル数は約384人です。
つまり、約400人のランダムな回答が得られれば、数万人規模の母集団の傾向をかなり正確に把握できます。ビジネスの現場では、スピードとコストを優先し、この「400サンプル」を目安にするのが一つの最適解です。
まとめ|母集団と標本を制する者はデータを制す
母集団と標本の違いを正しく理解することは、データリテラシーの基本にして奥義です。私たちは全知全能ではないため、すべての真実(母数)を知ることはできません。
しかし、適切な標本抽出と統計的な推論を用いることで、限られた情報から全体像を高い精度で描き出すことができます。今回紹介した黄金ルールを活用し、不確実な世界の中で確かな意思決定を行っていきましょう。