
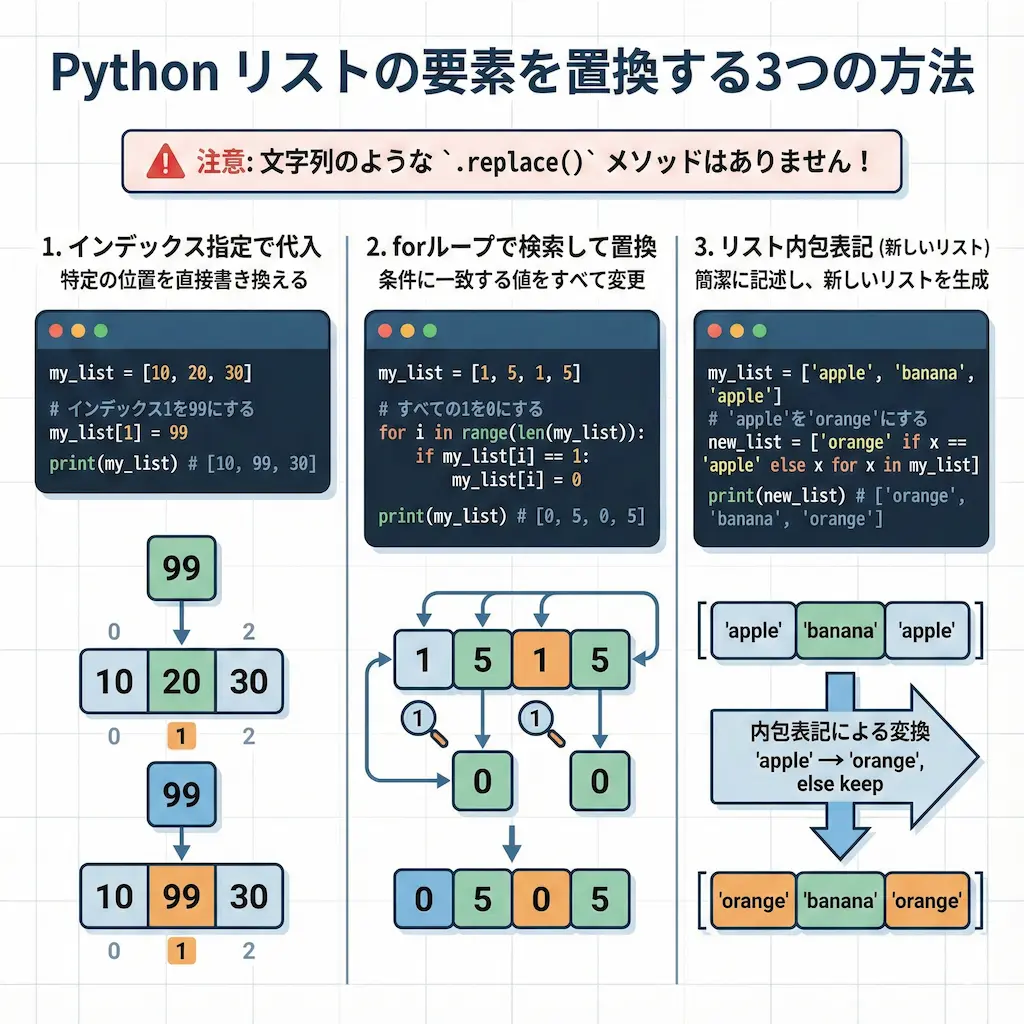
Pythonでデータ処理をしていると、リスト内の特定要素をまとめて書き換えたいシーンによく遭遇します。forループで一つずつ処理していては、コードが長くなるうえに処理速度も上がりません。
私が実務で最も推奨するのは、リスト内包表記を使ったシンプルかつ高速な手法です。データ量が膨大な場合はNumPyなどのライブラリを活用することで、劇的なパフォーマンス改善が見込めます。本記事では、初心者から上級者まで使える置換テクニックを網羅的に解説します。
Pythonリスト置換の基本|なぜ単純なループ処理は推奨されないのか
プログラミングを始めたばかりの頃は、for文を使って要素を一つずつ確認し、書き換える方法を思いつくでしょう。確かに動作はしますが、Pythonのリスト構造を理解していないと深刻なパフォーマンス低下やバグを招く原因になります。ここでは、避けるべきアンチパターンと、その改良版について解説します。
for文とindexメソッドの危険な組み合わせ
初心者の方がやりがちな間違いとして、forループの中で index() メソッドを使って要素の位置を探す方法があります。これは計算量が爆発的に増えるため、絶対に避けるべき書き方です。index() はリストの先頭から順番に値を探索するため、ループの中で使うと「リストの長さ × リストの長さ」分の時間がかかってしまいます。さらに、リスト内に同じ値が複数ある場合、常に最初の要素しか見つけられないという論理的なバグも含んでいます。意図しない挙動を引き起こすため、このアプローチは採用しないでください。
enumerate関数を使った正しいアプローチ
命令的なループ処理を行いたい場合、正解は enumerate() 関数を使うことです。この関数を使えば、インデックスと要素の値を同時に取得できるため、わざわざ検索する必要がありません。
# 値が3なら10に書き換える
for i, value in enumerate(my_list):
if value == 3:
my_list[i] = 10このように書くことで、計算量を最小限に抑えつつ安全にリストを更新できます。単純な値の置換であれば問題ありませんが、ループ中にリストの要素数を変える操作(削除や追加)は行わないでください。内部的な整合性が崩れ、予期せぬエラーの原因になります。
リスト内包表記とスライス代入|Pythonicな書き方をマスターする
Pythonには「リスト内包表記」という、リスト生成や操作に特化した強力な構文があります。可読性が高く、処理速度も通常のループより高速であるため、これを使いこなすことが脱初心者の第一歩です。ここでは、現場で即戦力となるテクニックを紹介します。
条件付きロジックを一行で書く技術
リスト内包表記を使えば、条件に応じた置換処理をたった一行で記述できます。三項演算子(条件式)を組み合わせるのがポイントです。
# 3を10に置換、それ以外はそのまま
new_list = [10 if x == 3 else x for x in my_list]この書き方は非常に高速で、誰が見ても「何をしたいか」が明確に伝わります。複雑な条件分岐も記述できますが、ネストが深くなると可読性が落ちるため注意が必要です。条件が複雑になる場合は、処理を別の関数に切り出す判断も重要になります。
スライス代入によるメモリ効率の改善
リストそのものの参照(ID)を変えずに中身だけをごっそり入れ替えたい場合は、「スライス代入」というテクニックを使います。変数の後に [:] を付けることで、リストのメモリ領域を維持したまま内容を更新できます。
# リストのIDを変えずに中身を一括更新
my_list[:] = [10 if x == 3 else x for x in my_list]この手法は、関数の引数として渡されたリストを直接書き換えたい場合に威力を発揮します。ただし、右辺のリストが一度メモリ上に生成されるため、一時的にメモリ使用量が増える点には注意してください。メモリ効率が最優先される場面では、後述するNumPyの活用を検討すべきです。
文字列リストにおける高速置換メソッド
リストの中身が文字列の場合、Pythonが標準で持っている文字列メソッドを活用するのが最速です。文字列の一部を置換したいなら、リスト内包表記と str.replace() を組み合わせます。
data = ["hello world", "world of code"]
res = [s.replace("world", "universe") for s in data]一文字単位の置換であれば、str.translate() を使うとさらに高速に処理できます。正規表現を使う re.sub() は強力ですが、単純な置換に使うにはオーバーヘッドが大きすぎます。用途に合わせてメソッドを選び分けることが、パフォーマンス向上の鍵です。
データ規模別の最適解|NumPyとPandasの導入基準
数万件を超えるデータを扱う場合、Python標準のリストでは処理速度に限界が来ます。データサイエンスの分野で標準的に使われるライブラリを導入することで、処理時間を数十分の一に短縮できます。ここでは、大規模データに対するアプローチを解説します。
NumPyによるベクトル化演算の威力
数値データを扱うなら、NumPy配列(ndarray)を使うのが圧倒的に有利です。NumPyは「ブールインデックス」という機能を持っており、条件に合う要素を一瞬で特定して書き換えられます。
import numpy as np
arr = np.array(my_list)
# すべての3を10に一括置換
arr[arr == 3] = 10この処理はC言語レベルで最適化されたループが実行されるため、Pythonのforループとは比べ物にならないほど高速です。複雑な条件には np.where や np.select を使うことで、柔軟かつ高速なデータ操作を実現できます。
Pandasでのデータ置換と注意点
表形式のデータを扱うPandasには replace() と map() という二つの置換メソッドがありますが、使い分けには注意が必要です。replace() は辞書にない値をそのまま維持しますが、map() は辞書にない値をすべて欠損値(NaN)に変換してしまいます。
| 特性 | replace() | map() |
|---|---|---|
| 未定義値 | 元の値を維持 | NaN(欠損値)になる |
| 主な用途 | 部分的な修正 | 全データの変換・正規化 |
| 注意点 | 型が勝手に変わることがある | 部分置換には不向き |
Pandasでは置換によってデータ型が勝手に変わる「サイレントな型変換」が発生することがあります。整数列に欠損値が入ると自動的に浮動小数点型(float)に変わってしまうため、意図しないデータ型の変化には常に警戒してください。
手法ごとのメリット・デメリット|状況に応じた使い分け
ここまで紹介した手法には、それぞれ得意な状況と不得意な状況があります。最適な手法を選ぶために、各アプローチの利点と欠点を整理します。コードを書く前の判断材料として活用してください。
標準機能(リスト内包表記)の評価
Python標準機能の最大のメリットは、追加のライブラリインストールが不要で、小回りが利く点です。
- メリット
- 外部ライブラリへの依存がないため、環境構築が容易に行えます。
- 構文がシンプルで可読性が高く、保守性に優れています。
- 小〜中規模(数千件程度)のデータであれば十分高速に動作します。
- デメリット
- 数百万件を超える大規模データでは処理速度が著しく低下します。
- 複雑な数値計算を含む場合、メモリ効率が悪くなる傾向があります。
日常的なスクリプト作成や、Web開発のバックエンド処理などでは、この標準機能だけで十分に対応できます。
外部ライブラリ(NumPy/Pandas)の評価
データ分析や機械学習の文脈では、外部ライブラリの利用が前提となります。
- メリット
- ベクトル化演算により、大規模データでも爆速で処理できます。
- 多次元配列や表形式データなど、複雑な構造を一括で扱えます。
- 条件分岐や欠損値処理など、高度な機能が豊富に用意されています。
- デメリット
- ライブラリのインポートが必要で、スクリプトの起動時間がわずかに延びます。
- 型(Type)に対する厳密な理解が必要で、学習コストがかかります。
- 単純なリスト操作に使うにはオーバースペックで、逆に遅くなることもあります。
画像のピクセル操作やログデータの解析など、パフォーマンスが要求される場面では迷わずこちらを選んでください。
まとめ|リスト置換はデータ規模で選ぶのが正解
Pythonでのリスト要素の置換は、データの規模と目的によって最適な手段が異なります。数千件までの日常的なデータ処理であれば、可読性と記述のしやすさを優先して「リスト内包表記」を使ってください。一方で、数万件を超える数値データや分析業務においては、「NumPy」や「Pandas」の活用が必須です。
あなたができる次のステップ:
今書いているコードの中で、forループとif文を使ってリストを書き換えている箇所を探し、まずは「リスト内包表記」に書き換えてみてください。コードが驚くほどスッキリするはずです。