私たちの生活において、SiriやAlexa、そしてChatGPTとの音声対話は当たり前のものとなりました。かつては「ロボットのような声」や「聞き取ってくれない耳」に失望した経験がある方も多いでしょうが、今やその精度は人間と区別がつかないレベルに達しています。
この劇的な進化の裏側には、ディープラーニング(深層学習)による技術的なパラダイムシフトが存在します。本記事では、音声認識(ASR)と音声合成(TTS)がどのように進化し、現在どのような仕組みで動いているのかを解説します。
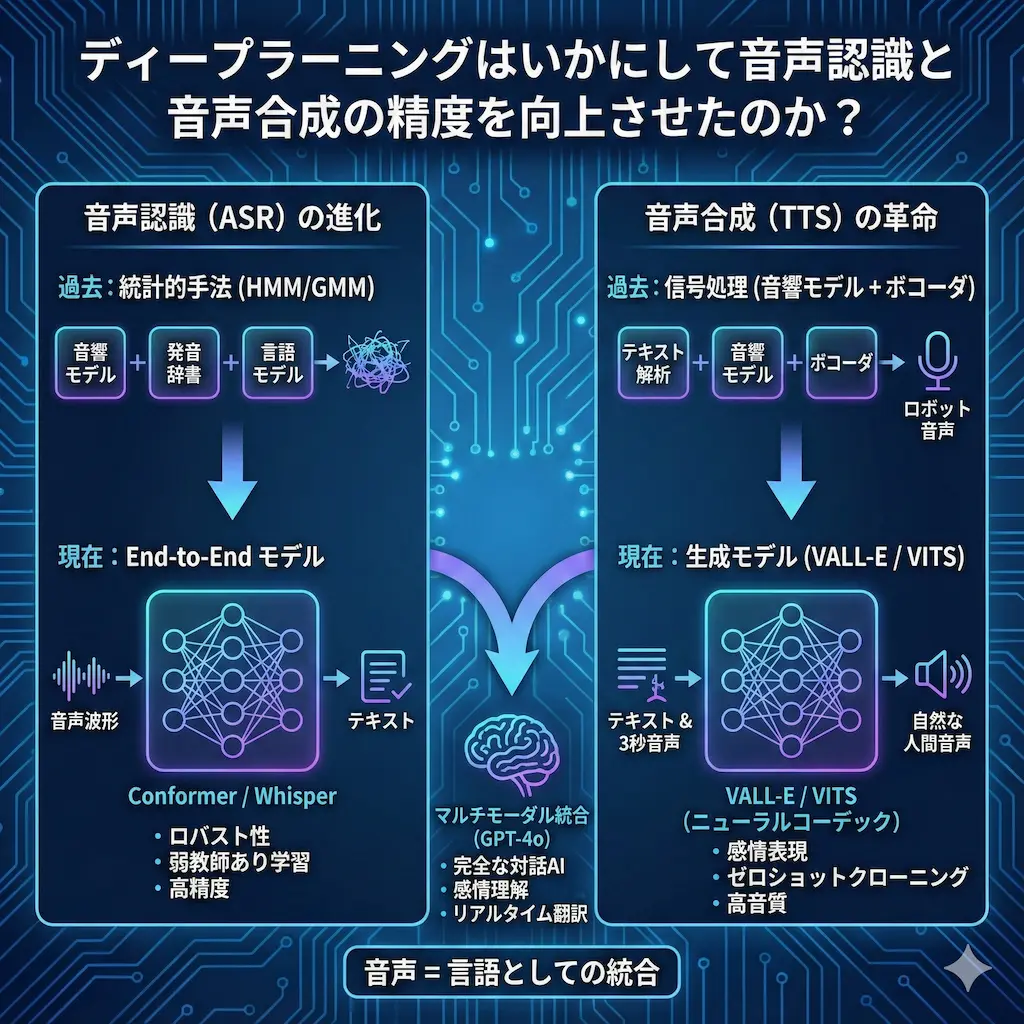
音声認識(ASR)の進化|End-to-Endモデルの台頭
音声認識技術は、統計的な手法からニューラルネットワークを用いたEnd-to-Endモデルへと移行することで、劇的な性能向上を果たしました。以前の手法では、発音辞書や音響モデルといった複数の部品を個別に調整する必要がありましたが、現在は一つの巨大なネットワークで完結できます。
従来のパイプラインからEnd-to-Endへ
かつての音声認識システムは、隠れマルコフモデル(HMM)やガウス混合モデル(GMM)を組み合わせた非常に複雑なパイプラインで構成されていました。この方式は専門知識を要する手作業の工程が多く、システム全体の最適化が困難だという課題を抱えていました。
ディープラーニングの導入により、音声波形を入力して直接テキストを出力するEnd-to-End(E2E)アーキテクチャが主流となりました。これにより、特徴量エンジニアリングの手間が省け、大量のデータセットを用いて認識精度を飛躍的に高めることができます。
主力アーキテクチャ|CTC、RNN-T、Attention
E2Eモデルには主に3つのアプローチがあり、それぞれが異なる特性を持っています。Connectionist Temporal Classification(CTC)は、推論が高速であるため並列計算に向いていますが、文脈を理解する能力には限界があります。
Recurrent Neural Network Transducer(RNN-T)は、ストリーミング処理に適しており、現在のスマートスピーカーやスマホの音声入力で標準的に使われている技術です。一方で、Attentionベースのエンコーダ・デコーダモデルは、音声全体を見て処理するため遅延は発生しますが、非常に高い認識精度を誇ります。
Conformerの登場と覇権
現在、音声認識のエンコーダ部分でデファクトスタンダードとなっているのが、Googleが提案した「Conformer」です。これは、全体を見るのが得意なTransformerと、局所的な特徴を捉えるのが得意なCNN(畳み込みニューラルネットワーク)を組み合わせた「サンドイッチ構造」をしています。
Conformerは、従来のモデルよりも少ない計算資源で高い精度を出せることが特徴です。NVIDIAなどが開発した派生モデルでは、認識精度を維持したまま推論速度を数倍に高めることに成功しており、産業界でも広く採用されています。
Whisperがもたらした弱教師あり学習の衝撃
2022年にOpenAIが発表したWhisperは、ウェブ上の68万時間という膨大な音声データを使って学習されました。これまでのモデルは綺麗に整えられたデータで学習するのが一般的でしたが、Whisperはノイズ混じりのデータもそのまま学習に使っています。
その結果、現実世界の雑音が多い環境や、多様なアクセントに対しても極めて強い耐性を持つようになりました。特定のテスト環境でのスコアよりも、実用的な「使い勝手の良さ」において、Whisperは圧倒的な性能を発揮します。
音声合成(TTS)の革命|生成モデルへの転換
音声合成の世界もまた、信号処理の技術から言語モデリングの技術へと変貌を遂げました。昔のような不自然な継ぎぎのある音声ではなく、息遣いや感情まで再現できる生成AIへと進化しています。
音響モデルとボコーダの統合
初期のディープラーニング音声合成は、テキストを音の特徴量に変換する「音響モデル」と、そこから音声を生成する「ボコーダ」の2段階に分かれていました。Tacotron 2やWaveNetといったモデルが高い品質を実現しましたが、推論に時間がかかるという欠点がありました。
その後、HiFi-GANのような高速かつ高音質なボコーダが登場し、リアルタイムでの合成が容易になりました。さらに現在では、これらの工程を一つにまとめたVITSのような完全なEnd-to-Endモデルが登場し、より人間らしく多様な韻律(リズムや抑揚)を表現できます。
VALL-Eとニューラルコーデック言語モデル
Microsoftが発表したVALL-Eは、音声を「波形」としてではなく、テキストのような「トークン(記号の列)」として扱うことでパラダイムシフトを起こしました。音声を離散的なコードに変換し、それを言語モデルで予測するという手法をとっています。
このアプローチにより、たった3秒間の声を聴かせるだけで、その人の声質や話し方を完全に模倣する「ゼロショット音声クローニング」が実現しました。GPT-3がテキストの続きを予測するように、VALL-Eは音声の続きを予測して生成します。
感情や背景音の再現
VALL-Eのようなモデルの驚くべき点は、単に声を真似るだけでなく、録音環境の音響特性まで再現できることです。電話越しの音声であれば電話のような音質で、静かな部屋であればクリアな音質で続きを生成します。
これは、従来の音声合成技術では難しかった「パラ言語情報(感情や雰囲気)」の学習に成功していることを意味します。テキスト情報だけでなく、音声に含まれるニュアンスそのものをモデルが理解し始めているのです。
マルチモーダル化と今後の展望
現在、音声認識と音声合成の境界線は曖昧になりつつあり、両者は大規模言語モデル(LLM)の一部として統合され始めています。音声はもはや単なる「音」ではなく、AIが理解できる「言語」の一つとして扱われています。
GPT-4oに見る音声と言語の融合
OpenAIのGPT-4oは、テキスト、音声、画像を単一のモデルで処理する「Omni-modal」なアーキテクチャを採用しました。これまでのAIは、一度音声をテキストに変換してから処理していましたが、GPT-4oは音声を直接理解します。
これにより、笑い声や悲しみ、皮肉といった感情表現を含んだ対話が実現しました。人間の会話における「割り込み」や「相槌」といったタイミングも学習しており、SF映画で見たような自然なコミュニケーションが現実のものとなっています。
オープンソースエコシステムの充実
研究開発の加速を支えているのが、充実したオープンソースのツールキット群です。研究者やエンジニアは、目的に応じて最適なフレームワークを選択し、開発を進めています。
以下の表は、主要なツールキットの特徴をまとめたものです。
| ツールキット | 開発元 | 特徴 | 主な用途 |
|---|---|---|---|
| NVIDIA NeMo | NVIDIA | 産業用・高速 | 大規模学習、企業での製品化 |
| ESPnet | CMU他 | 研究用・多機能 | 最先端アルゴリズムの実験、論文実装 |
| SpeechBrain | Mila他 | 教育用・簡潔 | コードが読みやすく、学習用途に最適 |
| Hugging Face | HF | 手軽さ・共有 | モデルの配布、アプリへの組み込み |
このように、アカデミアで生まれた最新技術が、NeMoやHugging Faceを通じて即座に産業界で利用できるエコシステムが整っています。
倫理的な課題とディープフェイク
技術の進歩は素晴らしい恩恵をもたらしますが、同時に「声の盗用」やディープフェイクによる詐欺という新たなリスクも生み出しました。誰でも簡単に他人の声を生成できるようになった今、その音声が本物かどうかを見抜く技術が求められています。
電子透かし(Watermarking)のような、生成された音声に人間には聞こえない識別信号を埋め込む技術開発が急ピッチで進められています。今後は、技術的な性能向上だけでなく、社会的な安全性を担保する仕組み作りが重要になります。
まとめ
ディープラーニングは、音声認識と音声合成という二つの技術を、単なる信号処理から高度な知能処理へと進化させました。ConformerやWhisper、VALL-Eといったモデルの登場により、AIは言葉の意味だけでなく、声色や感情までも扱えるようになっています。
私たちは今、キーボードや画面を介さずに、AIと声だけで心を通わせることができる時代の入り口に立っています。この技術革新は、コミュニケーションのあり方を根底から変える力を持っています。